{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 quanzx 的文章《关于位结构体及位操作总结》','https://www.xiaopingtou.net/article-84108.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
c语言中 关于位结构体 及 位操作总结:
位结构体
(参考网址)
位域 有些信息在存储时,并不需要占用一个完整的字节, 而只需占几个或一个二进制位。例如在存放一个开关量时,只有0和1 两种状态, 用一位二进位即可。 为了节省存储空间,并使处理简便,C语言又提供了一种数据结构,称为“位域”或“位段”。所谓“位域”是把一个字节中的二进位划分为几个不同的区域, 并 说明每个区域的位数。每个域有一个域名,允许在程序中按域名进行操作。 这样就可以把几个不同的对象用一个字节的二进制位域来表示。一、位域的定 义和位域变量的说明位域定义与结构定义相仿,其形式为:
struct 位域结构名
{ 位域列表 };
其中位域列表的形式为: 类型说明符 位域名:位域长度 例如:
[cpp] view plain copy
位域变量的说明与结构变量说明的方式相同。 可采用先定义后说明,同时定义说明或者直接说明这三种方式。例如:
[cpp] view plain copy
说明data为bs变量,共占两个字节。其中位域a占8位,位域b占2位,位域c占6位。对于位域的定义尚有以下几点说明: 1. 一个位域必须存储在同一个字节中,不能跨两个字节。如一个字节所剩空间不够存放另一位域时,应从下一单元起存放该位域。也可以有意使某位域 从下一单元开始。例如:
[cpp] view plain copy
在这个位域定义中,a占第一字节的4位,后4位填0表示不使用,b从第二字节开始,占用4位,c占用4位。 2. 由于位域不允许跨两个字节,因此位域的长度不能大于一个字节的长度,也就是说不能超过8位二进位。 3. 位域可以无位域名,这时它只用来作填充或调整位置。无名的位域是不能使用的。例如:
[cpp] view plain copy
从以上分析可以看出,位域在本质上就是一种结构类型, 不过其成员是按二进位分配的。 位域的使用 位域的使用和结构成员的使用相同,其一般形式为: 位域变量名·位域名 位域允许用各种格式输出。
[cpp] view plain copy
上例程序中定义了位域结构A,两个个位域为a(占用5位),b(占用3位),所以a和b总共占用了结构A一个字节(低位的一个字节)。
结构体st内存分配情况(因为字符’0‘对于的assic码为 48,转换为8bit的二进制位为 0011 0000):
高位 00110011 00110010 00110001 00110000 低位
'3' '2' '1' '0'
其中st.a和st.b占用st低位一个字节(00110000),st.a : 10000, st.b : 001 输出结果为: T.a=-16 T.b=1
解释:
st.a内存中二进制表示为10000,由于st.a为有符号的整型变量,输出时要对符号位进行扩展, 所以结果为-16(二进制为11111111111111111111111111110000).符号扩展和截断的几点认识,点我。
st.b内存中二进制表示为001,由于st.b为有符号的整型变量,输出时要对符号位进行扩展, 所以结果为1(二进制为00000000000000000000000000000001)
再来一例:
写出下列程序在X86上的运行结果。
[cpp] view plain copy
这个题的为难之处呢,就在于前面定义结构体里面用到的冒号,如果你能理解这个符号的含义,那么问题就很好解决了。
这里的冒号相当于分配几位空间,也即在定义结构体的时候,分配的成员a 4位的空间, b 5位,c7位,一共是16位,正好
两个字节。下面画一个简单的示意:
变量名 位数
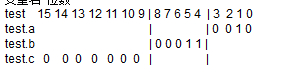
两个字节为 0000 0000 0011 0010
在执行i=*((short *)&test);时,取从地址&test开始两个字节(short占两个字节)的内容转化为short型数据,即为0x0032,
再转为int型为0x00000032,即50。输出的结果就是50。当然,这里还涉及到字节及位的存储顺序问题,后面再说。
前面定义的结构体被称为位结构体。所谓位结构体,是一种特殊的结构体,在需要按位访问字节或字的一个或多个位时,
位结构体比按位操作要更方便一些。位结构体的定义方式如下: struct [位结构体名]
{ 数据类型 变量名:整数常数; ... }位结构变量; 说明: 1)这里的数据类型只能为int型(包括signed和unsigned); 2)整数常数必须为0~15之间的整数,当该常数为1时,数据类型为unsigned(显然嘛,只有一位,咋表示signed?光一符号?没意义呀); 3)按数据类型变量名:整数常数;方式定义的结构成员称为位结构成员,好像也叫位域,在一个位结构体中,可以同时包含位结构成员及普通的结构成员; 4)位结构成员不能是指针或数据,但结构变量可以是指针或数据; 5)位结构体所占用的位数由各个位结构成员的位数总各决定。如在前面定义的结构体中,一共占用4+5+7=16位,两个字节。另外我们看到,在定义位
结构成员时,必须指定数据类型,这个数据类型在位结构体占用多少内存时也起到不少的作用。举个例子:
struct mybitfieldA{ char a:4; char b:3; }testA; struct mybitfieldB{ short a:4; short b:3; }testB; 这里,testA占用一个字节,而testB占用两个字节。知道原因了吧。在testA中,是以char来定义位域的,char是一个字节的,因此,位域占用的单位也按
字节做单位,也即,如果不满一个字节的话按一个字节算(未定义的位按零处理)。而在testB中,short为两个字节,所以了,不满两个字节的都按两个
字节算(未定义位按零处理)。 关于位结构体在内存中的存储问题 Kevin's Theory #2: In a C structure that contains bit fields,if field A is defined in front of field B, then field A alwaysoccupies a lower bit address than field B.
(来自http://www.linuxforum.net/forum/showflat.php?Cat=&Board=linuxk&Number=638637&page=0&view=collapsed&sb=5&o=all&fpart=all) 说的是,在C结构体中,如果一个位域A在另一个位域B之前定义,那么位域A将存储在比B小的位地址中。 如果一个位域有多个位时,各个位的排列顺序通常是按CPU的端模式(Endianess)来进行的,即在大端模式(bigendian)下,高有效位在低位地址,小端模式
则相反。补充说明一个关于位域与普通结构成员一起使用的问题 先看一个例子 struct mybitfield{ char a:4; char b:3; char aa; char c:1;}test; 这种情况下,test应该占几个字节呢?2个(4+3+1=8占一个字节,aa占一个)还是3个(4+3不足补一位,占一个字节,aa占一个字节,c占一个字节)? 写个小程序验证一下: int main()
{
int i;
test.a = 1;
test.b = 1;
test.aa = 1;
test.c = 1; i=*((short*)&test);
printf("%d ",i); return 0;
} 输出结果是273,化为十六进制数0x111,可见是按三个字节来处理了(如果按两个字节处理的话,cba组成一个字节,是10010001(十六进制0x91)再加上aa, 那就应该是0x191了)举这个例子是为了说明一下,定义位域的话,最好是把所有位域放在一起,这样可以节省空间(如果把c和aa换一下位置,那test就只占两个 字节了)。另外也是为了强调一下位结构体的内存分配方式,按定义的先后顺序来分配,而位域(或成员)内的字节顺序则按照CPU的位顺序来进行(一般与CPU 的端模式对应)。
内存对齐
许多计算机系统对基本类型数据在内存中存放的位置有限制,它们会要求这些数据的首地址的值是某个数k(通常它为4或8)的倍数,这就是所谓的内存对齐,
而这个k则被称为该数据类型的对齐模数(alignment modulus)。当一种类型S的对齐模数与另一种类型T的对齐模数的比值是大于1的整数,我们就称类型
S的对齐要求比T强(严格),而称T比S弱(宽松)。这种强制的要求一来简化了处理器与内存之间传输系统的设计,二来可以提升读取数据的速度。比如这么
一种处理器,它每次读写内存的时候都从某个8倍数的地址开始,一次读出或写入8个字节的数据,假如软件能保证double类型的数据都从8倍数地址开始,
那么读或写一个double类型数据就只需要一次内存操作。否则,我们就可能需要两次内存操作才能完成这个动作,因为数据或许恰好横跨在两个符合对齐
要求的8字节内存块上。某些处理器在数据不满足对齐要求的情况下可能会出错,但是Intel的IA32架构的处理器则不管数据是否对齐都能正确工作。不过
Intel奉劝大家,如果想提升性能,那么所有的程序数据都应该尽可能地对齐。
ANSI C标准中并没有规定,相邻声明的变量在内存中一定要相邻。为了程序的高效性,内存对齐问题由编译器自行灵活处理,这样导致相邻的变量之间
可能会有一些填充字节。对于基本数据类型(int char),他们占用的内存空间在一个确定硬件系统下有个确定的值,所以,接下来我们只是考虑结构体成员
内存分配情况。
根据以上准则,在windows下,使用VC编译器,sizeof(T)的大小为8个字节。 而在GNU GCC编译器中,遵循的准则有些区别,对齐模数不是像上面所述的那样,根据最宽的基本数据类型来定。 在GCC中,对齐模数的准则是:对齐模数最大只能是4,也就是说,即使结构体中有double类型,对齐模数还是4,所以对齐模数只能是1,2,4。而且在上述 的三条中,第2条里,offset必须是成员大小的整数倍,如果这个成员大小小于等于4则按照上述准则进行,但是如果大于4了,则结构体每个成员相对于结构体首 地址的偏移量(offset)只能按照是4的整数倍来进行判断是否添加填充。
看如下例子: struct T
{
char ch;
double d ;
}; 那么在GCC下,sizeof(T)应该等于12个字节。 如果结构体中含有位域(bit-field),那么VC中准则又要有所更改:
1) 如果相邻位域字段的类型相同,且其位宽之和小于类型的sizeof大小,则后面的字段将紧邻前一个字段存储,直到不能容纳为止;
2) 如果相邻位域字段的类型相同,但其位宽之和大于类型的sizeof大小,则后面的字段将从新的存储单元开始,其偏移量为其类型大小的整数倍;
3) 如果相邻的位域字段的类型不同,则各编译器的具体实现有差异,VC6采取不压缩方式(不同位域字段存放在不同的位域类型字节中),Dev-C++和GCC都采取压缩方式;
备注:当两字段类型不一样的时候,对于不压缩方式,例如: struct N
{
char c:2;
int i:4;
}; 依然要满足不含位域结构体内存对齐准则第2条,i成员相对于结构体首地址的偏移应该是4的整数倍,所以c成员后要填充3个字节,然后再开辟4个字节的空间作为int型, 其中4位用来存放i,所以上面结构体在VC中所占空间为8个字节;而对于采用压缩方式的编译器来说,遵循不含位域结构体内存对齐准则第2条,不同的是,如果填充的 3个字节能容纳后面成员的位,则压缩到填充字节中,不能容纳,则要单独开辟空间,所以上面结构体N在GCC或者Dev-C++中所占空间应该是4个字节。 4) 如果位域字段之间穿插着非位域字段,则不进行压缩;
备注:
结构体5) 整个结构体的总大小为最宽基本类型成员大小的整数倍。 typedef struct
{
char c:2;
double i;
int c2:4;
}N3; 在GCC下占据的空间为16字节,在VC下占据的空间应该是24个字节。 ps: A,对齐模数的选择只能是根据基本数据类型,所以对于结构体中嵌套结构体,只能考虑其拆分的基本数据类型。而对于对齐准则中的第2条,确是要将整个结构体看成是
一个成员,成员大小按照该结构体根据对齐准则判断所得的大小。
B,类对象在内存中存放的方式和结构体类似,这里就不再说明。需要指出的是,类对象的大小只是包括类中非静态成员变量所占的空间,如果有虚函数,那么再另外增加
一个指针所占的空间即可。
1.内存对齐与编译器设置有关,首先要搞清编译器这个默认值是多少 如果不想编译器默认的话,可以通过#pragma pack(n)来指定按照n对齐.
2. 每个结构体变量对齐,如果对齐参数n(编译器默认或者通过pragma指定)大于该变量所占字节数(m),那么就按照m对齐,内存偏移后的地址是m的倍数,否则是
按照n对齐,内存偏移后的地址是n的倍数。也就是最小化长度规则结构体总大小:对齐后的长度必须是成员中最大的对齐参数的整数倍。最大对齐参数是从第三步
得到的。
补充:如果结构体A中还要结构体B,那么B的对齐方式是选它里面最长的成员的对齐方式
位运算符C语言提供了六种位运算符: & 按位与
| 按位或
^ 按位异或
~ 取反
<< 左移
>> 右移
1. 按位与运算 按位与运算符"&"是双目运算符。其功能是参与运算的两数各对应的二进位相与。只有对应的两个二进位均为1时,结果位才为1 ,否则为0。参与运算的 数以补码方式出现。 例如:9&5可写算式如下: 00001001 (9的二进制补码)&00000101 (5的二进制补码) 00000001 (1的二进制补码)可见9&5=1。 按位与运算通常用来对某些位清0或保留某些位。例如把a 的高八位清 0 , 保留低八位, 可作 a&255 运算 ( 255 的二进制数为0000000011111111)。
main(){
int a=9,b=5,c;
c=a&b;
printf("a=%d/nb=%d/nc=%d/n",a,b,c);
}
2. 按位或运算 按位或运算符“|”是双目运算符。其功能是参与运算的两数各对应的二进位相或。只要对应的二个二进位有一个为1时,结果位就为1。参与运算的两个数均以 补码出现。
例如:9|5可写算式如下: 00001001|00000101
00001101 (十进制为13)可见9|5=13
main(){
int a=9,b=5,c;
c=a|b;
printf("a=%d/nb=%d/nc=%d/n",a,b,c);
} 3. 按位异或运算 按位异或运算符“^”是双目运算符。其功能是参与运算的两数各对应的二进位相异或,当两对应的二进位相异时,结果为1。参与运算数仍以补码出现, 例如9^5可写成算式如下: 00001001^00000101 00001100 (十进制为12)
main(){
int a=9;
a=a^15;
printf("a=%d/n",a);
} 4. 求反运算 求反运算符~为单目运算符,具有右结合性。 其功能是对参与运算的数的各二进位按位求反。例如~9的运算为: ~(0000000000001001)结果为:1111111111110110 5. 左移运算 左移运算符“<<”是双目运算符。其功能把“<< ”左边的运算数的各二进位全部左移若干位,由“<<”右边的数指定移动的位数,
高位丢弃,低位补0。例如: a<<4 指把a的各二进位向左移动4位。如a=00000011(十进制3),左移4位后为00110000(十进制48)。 6. 右移运算 右移运算符“>>”是双目运算符。其功能是把“>> ”左边的运算数的各二进位全部右移若干位,“>>”右边的数指定移动的位数。
例如:设 a=15,a>>2 表示把000001111右移为00000011(十进制3)。 应该说明的是,对于有符号数,在右移时,符号位将随同移动。当为正数时, 最高位补0,而为负数时,符号位为1,最高位是补0或是补1 取决于编译系统的规定。Turbo C和很多系统规定为补1。
main(){
unsigned a,b;
printf("input a number: ");
scanf("%d",&a);
b=a>>5;
b=b&15;
printf("a=%d/tb=%d/n",a,b);
}
请再看一例!
main(){
char a='a',b='b';
int p,c,d;
p=a;
p=(p<<8)|b;
d=p&0xff;
c=(p&0xff00)>>8;
printf("a=%d/nb=%d/nc=%d/nd=%d/n",a,b,c,d);
}
二进制 补码 的简便求法: 正的二进制数的补码就是原码。 负的二进制数的补码,符号位为1,其余位为该数绝对值的原码按位取反;然后整个数加1。 (1)、在计算机系统中,数值一律用补码来表示(存储)。 主要原因:使用补码,可以将符号位和其它位统一处理;同时,减法也可按加法来处理。 另外,两个用补 码表示的数相加时,如果最高位(符号位)有进位,则进位被舍弃。 (2)、补码与原码的转换过程几乎是相同的。补码的补码即是原码。
参考:
http://blog.csdn.net/xing_hao/article/details/6677809
http://baike.baidu.com/link?url=q8XiHf_3PZni8FJG_2oZBHoX61Clh7i2eWikfAm-iIeOIYpjB7JhK-a2z2y4nrmNBDYn0razNNiucBBkQeWK_a
位结构体
(参考网址)位域 有些信息在存储时,并不需要占用一个完整的字节, 而只需占几个或一个二进制位。例如在存放一个开关量时,只有0和1 两种状态, 用一位二进位即可。 为了节省存储空间,并使处理简便,C语言又提供了一种数据结构,称为“位域”或“位段”。所谓“位域”是把一个字节中的二进位划分为几个不同的区域, 并 说明每个区域的位数。每个域有一个域名,允许在程序中按域名进行操作。 这样就可以把几个不同的对象用一个字节的二进制位域来表示。一、位域的定 义和位域变量的说明位域定义与结构定义相仿,其形式为:
struct 位域结构名
{ 位域列表 };
其中位域列表的形式为: 类型说明符 位域名:位域长度 例如:
[cpp] view plain copy
- struct bs
- {
- int a:8;
- int b:2;
- int c:6;
- };
位域变量的说明与结构变量说明的方式相同。 可采用先定义后说明,同时定义说明或者直接说明这三种方式。例如:
[cpp] view plain copy
- struct bs
- {
- int a:8;
- int b:2;
- int c:6;
- }data;
说明data为bs变量,共占两个字节。其中位域a占8位,位域b占2位,位域c占6位。对于位域的定义尚有以下几点说明: 1. 一个位域必须存储在同一个字节中,不能跨两个字节。如一个字节所剩空间不够存放另一位域时,应从下一单元起存放该位域。也可以有意使某位域 从下一单元开始。例如:
[cpp] view plain copy
- struct bs
- {
- unsigned a:4
- unsigned :0 /*空域*/
- unsigned b:4 /*从下一单元开始存放*/
- unsigned c:4
- }
在这个位域定义中,a占第一字节的4位,后4位填0表示不使用,b从第二字节开始,占用4位,c占用4位。 2. 由于位域不允许跨两个字节,因此位域的长度不能大于一个字节的长度,也就是说不能超过8位二进位。 3. 位域可以无位域名,这时它只用来作填充或调整位置。无名的位域是不能使用的。例如:
[cpp] view plain copy
- struct k
- {
- int a:1
- int :2 /*该2位不能使用*/
- int b:3
- int c:2
- };
从以上分析可以看出,位域在本质上就是一种结构类型, 不过其成员是按二进位分配的。 位域的使用 位域的使用和结构成员的使用相同,其一般形式为: 位域变量名·位域名 位域允许用各种格式输出。
[cpp] view plain copy
-
#include
-
#include
- typedef struct
- {
- int a:5;
- int b:3;
- }T;
- int main(void)
- {
- char str[] = "0123456";
- T st;
- memcpy(&st, str, sizeof(T));
- printf("T.a=%d T.b=%d ", st.a, st.b);
- return 0;
- }
上例程序中定义了位域结构A,两个个位域为a(占用5位),b(占用3位),所以a和b总共占用了结构A一个字节(低位的一个字节)。
结构体st内存分配情况(因为字符’0‘对于的assic码为 48,转换为8bit的二进制位为 0011 0000):
高位 00110011 00110010 00110001 00110000 低位
'3' '2' '1' '0'
其中st.a和st.b占用st低位一个字节(00110000),st.a : 10000, st.b : 001 输出结果为: T.a=-16 T.b=1
解释:
st.a内存中二进制表示为10000,由于st.a为有符号的整型变量,输出时要对符号位进行扩展, 所以结果为-16(二进制为11111111111111111111111111110000).符号扩展和截断的几点认识,点我。
st.b内存中二进制表示为001,由于st.b为有符号的整型变量,输出时要对符号位进行扩展, 所以结果为1(二进制为00000000000000000000000000000001)
再来一例:
写出下列程序在X86上的运行结果。
[cpp] view plain copy
-
#include
- struct mybitfields
- {
- unsigned short a : 4;
- unsigned short b : 5;
- unsigned short c : 7;
- }test;
- int main()
- {
- int i;
- test.a=2;
- test.b=3;
- test.c=0;
- i=*((short *)&test);
- printf("%d ",i);
- return 0;
- }
这个题的为难之处呢,就在于前面定义结构体里面用到的冒号,如果你能理解这个符号的含义,那么问题就很好解决了。
这里的冒号相当于分配几位空间,也即在定义结构体的时候,分配的成员a 4位的空间, b 5位,c7位,一共是16位,正好
两个字节。下面画一个简单的示意:
变量名 位数
两个字节为 0000 0000 0011 0010
在执行i=*((short *)&test);时,取从地址&test开始两个字节(short占两个字节)的内容转化为short型数据,即为0x0032,
再转为int型为0x00000032,即50。输出的结果就是50。当然,这里还涉及到字节及位的存储顺序问题,后面再说。
前面定义的结构体被称为位结构体。所谓位结构体,是一种特殊的结构体,在需要按位访问字节或字的一个或多个位时,
位结构体比按位操作要更方便一些。位结构体的定义方式如下: struct [位结构体名]
{ 数据类型 变量名:整数常数; ... }位结构变量; 说明: 1)这里的数据类型只能为int型(包括signed和unsigned); 2)整数常数必须为0~15之间的整数,当该常数为1时,数据类型为unsigned(显然嘛,只有一位,咋表示signed?光一符号?没意义呀); 3)按数据类型变量名:整数常数;方式定义的结构成员称为位结构成员,好像也叫位域,在一个位结构体中,可以同时包含位结构成员及普通的结构成员; 4)位结构成员不能是指针或数据,但结构变量可以是指针或数据; 5)位结构体所占用的位数由各个位结构成员的位数总各决定。如在前面定义的结构体中,一共占用4+5+7=16位,两个字节。另外我们看到,在定义位
结构成员时,必须指定数据类型,这个数据类型在位结构体占用多少内存时也起到不少的作用。举个例子:
struct mybitfieldA{ char a:4; char b:3; }testA; struct mybitfieldB{ short a:4; short b:3; }testB; 这里,testA占用一个字节,而testB占用两个字节。知道原因了吧。在testA中,是以char来定义位域的,char是一个字节的,因此,位域占用的单位也按
字节做单位,也即,如果不满一个字节的话按一个字节算(未定义的位按零处理)。而在testB中,short为两个字节,所以了,不满两个字节的都按两个
字节算(未定义位按零处理)。 关于位结构体在内存中的存储问题 Kevin's Theory #2: In a C structure that contains bit fields,if field A is defined in front of field B, then field A alwaysoccupies a lower bit address than field B.
(来自http://www.linuxforum.net/forum/showflat.php?Cat=&Board=linuxk&Number=638637&page=0&view=collapsed&sb=5&o=all&fpart=all) 说的是,在C结构体中,如果一个位域A在另一个位域B之前定义,那么位域A将存储在比B小的位地址中。 如果一个位域有多个位时,各个位的排列顺序通常是按CPU的端模式(Endianess)来进行的,即在大端模式(bigendian)下,高有效位在低位地址,小端模式
则相反。补充说明一个关于位域与普通结构成员一起使用的问题 先看一个例子 struct mybitfield{ char a:4; char b:3; char aa; char c:1;}test; 这种情况下,test应该占几个字节呢?2个(4+3+1=8占一个字节,aa占一个)还是3个(4+3不足补一位,占一个字节,aa占一个字节,c占一个字节)? 写个小程序验证一下: int main()
{
int i;
test.a = 1;
test.b = 1;
test.aa = 1;
test.c = 1; i=*((short*)&test);
printf("%d ",i); return 0;
} 输出结果是273,化为十六进制数0x111,可见是按三个字节来处理了(如果按两个字节处理的话,cba组成一个字节,是10010001(十六进制0x91)再加上aa, 那就应该是0x191了)举这个例子是为了说明一下,定义位域的话,最好是把所有位域放在一起,这样可以节省空间(如果把c和aa换一下位置,那test就只占两个 字节了)。另外也是为了强调一下位结构体的内存分配方式,按定义的先后顺序来分配,而位域(或成员)内的字节顺序则按照CPU的位顺序来进行(一般与CPU 的端模式对应)。
内存对齐
许多计算机系统对基本类型数据在内存中存放的位置有限制,它们会要求这些数据的首地址的值是某个数k(通常它为4或8)的倍数,这就是所谓的内存对齐,
而这个k则被称为该数据类型的对齐模数(alignment modulus)。当一种类型S的对齐模数与另一种类型T的对齐模数的比值是大于1的整数,我们就称类型
S的对齐要求比T强(严格),而称T比S弱(宽松)。这种强制的要求一来简化了处理器与内存之间传输系统的设计,二来可以提升读取数据的速度。比如这么
一种处理器,它每次读写内存的时候都从某个8倍数的地址开始,一次读出或写入8个字节的数据,假如软件能保证double类型的数据都从8倍数地址开始,
那么读或写一个double类型数据就只需要一次内存操作。否则,我们就可能需要两次内存操作才能完成这个动作,因为数据或许恰好横跨在两个符合对齐
要求的8字节内存块上。某些处理器在数据不满足对齐要求的情况下可能会出错,但是Intel的IA32架构的处理器则不管数据是否对齐都能正确工作。不过
Intel奉劝大家,如果想提升性能,那么所有的程序数据都应该尽可能地对齐。
ANSI C标准中并没有规定,相邻声明的变量在内存中一定要相邻。为了程序的高效性,内存对齐问题由编译器自行灵活处理,这样导致相邻的变量之间
可能会有一些填充字节。对于基本数据类型(int char),他们占用的内存空间在一个确定硬件系统下有个确定的值,所以,接下来我们只是考虑结构体成员
内存分配情况。对齐规则(参考百度百科)
每个特定平台上的编译器都有自己的默认“对齐系数”(也叫对齐模数)。程序员可以通过预编译命令#pragma pack(n),n=1,2,4,8,16来改变这一系数,其中的n就是你要指定的“对齐系数”。 规则: 1、数据成员对齐规则:结构(struct)(或联合(union))的数据成员,第一个数据成员放在offset为0的地方,以后每个数据成员的对齐按照#pragma pack指定的数值和这个数据成员自身长度中,比较小的那个进行。 2、结构(或联合)的整体对齐规则:在数据成员完成各自对齐之后,结构(或联合)本身也要进行对齐,对齐将按照#pragma pack指定的数值和结构(或联合)最大数据成员长度中,比较小的那个进行。 3、结合1、2可推断:当#pragma pack的n值等于或超过所有数据成员长度的时候,这个n值的大小将不产生任何效果。 Win32平台下的微软C编译器(cl.exefor 80×86)的对齐策略: 1)结构体变量的首地址是其最长基本类型成员的整数倍; 备注:编译器在给结构体开辟空间时,首先找到结构体中最宽的基本数据类型,然后寻找内存地址能是该基本数据类型的整倍的位置,作为结构体的首地址。将这个最宽的基本数据类型的大小作为上面介绍的对齐模数。 2)结构体每个成员相对于结构体首地址的偏移量(offset)都是成员大小的整数倍,如有需要编译器会在成员之间加上填充字节(internal adding); 备注:为结构体的一个成员开辟空间之前,编译器首先检查预开辟空间的首地址相对于结构体首地址的偏移是否是本成员的整数倍,若是,则存放本成员,反之,则在本成员和上一个成员之间填充一定的字节,以达到整数倍的要求,也就是将预开辟空间的首地址后移几个字节。 3)结构体的总大小为结构体最宽基本类型成员大小的整数倍,如有需要,编译器会在最末一个成员之后加上填充字节(trailing padding)。 备注: a、结构体总大小是包括填充字节,最后一个成员满足上面两条以外,还必须满足第三条,否则就必须在最后填充几个字节以达到本条要求。 b、如果结构体内存在长度大于处理器位数的元素,那么就以处理器的倍数为对齐单位;否则,如果结构体内的元素的长度都小于处理器的倍数的时候,便以结构体里面最长的数据元素为对齐单位。 4) 结构体内类型相同的连续元素将在连续的空间内,和数组一样。根据以上准则,在windows下,使用VC编译器,sizeof(T)的大小为8个字节。 而在GNU GCC编译器中,遵循的准则有些区别,对齐模数不是像上面所述的那样,根据最宽的基本数据类型来定。 在GCC中,对齐模数的准则是:对齐模数最大只能是4,也就是说,即使结构体中有double类型,对齐模数还是4,所以对齐模数只能是1,2,4。而且在上述 的三条中,第2条里,offset必须是成员大小的整数倍,如果这个成员大小小于等于4则按照上述准则进行,但是如果大于4了,则结构体每个成员相对于结构体首 地址的偏移量(offset)只能按照是4的整数倍来进行判断是否添加填充。
看如下例子: struct T
{
char ch;
double d ;
}; 那么在GCC下,sizeof(T)应该等于12个字节。 如果结构体中含有位域(bit-field),那么VC中准则又要有所更改:
1) 如果相邻位域字段的类型相同,且其位宽之和小于类型的sizeof大小,则后面的字段将紧邻前一个字段存储,直到不能容纳为止;
2) 如果相邻位域字段的类型相同,但其位宽之和大于类型的sizeof大小,则后面的字段将从新的存储单元开始,其偏移量为其类型大小的整数倍;
3) 如果相邻的位域字段的类型不同,则各编译器的具体实现有差异,VC6采取不压缩方式(不同位域字段存放在不同的位域类型字节中),Dev-C++和GCC都采取压缩方式;
备注:当两字段类型不一样的时候,对于不压缩方式,例如: struct N
{
char c:2;
int i:4;
}; 依然要满足不含位域结构体内存对齐准则第2条,i成员相对于结构体首地址的偏移应该是4的整数倍,所以c成员后要填充3个字节,然后再开辟4个字节的空间作为int型, 其中4位用来存放i,所以上面结构体在VC中所占空间为8个字节;而对于采用压缩方式的编译器来说,遵循不含位域结构体内存对齐准则第2条,不同的是,如果填充的 3个字节能容纳后面成员的位,则压缩到填充字节中,不能容纳,则要单独开辟空间,所以上面结构体N在GCC或者Dev-C++中所占空间应该是4个字节。 4) 如果位域字段之间穿插着非位域字段,则不进行压缩;
备注:
结构体5) 整个结构体的总大小为最宽基本类型成员大小的整数倍。 typedef struct
{
char c:2;
double i;
int c2:4;
}N3; 在GCC下占据的空间为16字节,在VC下占据的空间应该是24个字节。 ps: A,对齐模数的选择只能是根据基本数据类型,所以对于结构体中嵌套结构体,只能考虑其拆分的基本数据类型。而对于对齐准则中的第2条,确是要将整个结构体看成是
一个成员,成员大小按照该结构体根据对齐准则判断所得的大小。
B,类对象在内存中存放的方式和结构体类似,这里就不再说明。需要指出的是,类对象的大小只是包括类中非静态成员变量所占的空间,如果有虚函数,那么再另外增加
一个指针所占的空间即可。
1.内存对齐与编译器设置有关,首先要搞清编译器这个默认值是多少 如果不想编译器默认的话,可以通过#pragma pack(n)来指定按照n对齐.
2. 每个结构体变量对齐,如果对齐参数n(编译器默认或者通过pragma指定)大于该变量所占字节数(m),那么就按照m对齐,内存偏移后的地址是m的倍数,否则是
按照n对齐,内存偏移后的地址是n的倍数。也就是最小化长度规则结构体总大小:对齐后的长度必须是成员中最大的对齐参数的整数倍。最大对齐参数是从第三步
得到的。
补充:如果结构体A中还要结构体B,那么B的对齐方式是选它里面最长的成员的对齐方式
C语言位运算符及常见用法
位运算符C语言提供了六种位运算符: & 按位与
| 按位或
^ 按位异或
~ 取反
<< 左移
>> 右移
1. 按位与运算 按位与运算符"&"是双目运算符。其功能是参与运算的两数各对应的二进位相与。只有对应的两个二进位均为1时,结果位才为1 ,否则为0。参与运算的 数以补码方式出现。 例如:9&5可写算式如下: 00001001 (9的二进制补码)&00000101 (5的二进制补码) 00000001 (1的二进制补码)可见9&5=1。 按位与运算通常用来对某些位清0或保留某些位。例如把a 的高八位清 0 , 保留低八位, 可作 a&255 运算 ( 255 的二进制数为0000000011111111)。
main(){
int a=9,b=5,c;
c=a&b;
printf("a=%d/nb=%d/nc=%d/n",a,b,c);
}
2. 按位或运算 按位或运算符“|”是双目运算符。其功能是参与运算的两数各对应的二进位相或。只要对应的二个二进位有一个为1时,结果位就为1。参与运算的两个数均以 补码出现。
例如:9|5可写算式如下: 00001001|00000101
00001101 (十进制为13)可见9|5=13
main(){
int a=9,b=5,c;
c=a|b;
printf("a=%d/nb=%d/nc=%d/n",a,b,c);
} 3. 按位异或运算 按位异或运算符“^”是双目运算符。其功能是参与运算的两数各对应的二进位相异或,当两对应的二进位相异时,结果为1。参与运算数仍以补码出现, 例如9^5可写成算式如下: 00001001^00000101 00001100 (十进制为12)
main(){
int a=9;
a=a^15;
printf("a=%d/n",a);
} 4. 求反运算 求反运算符~为单目运算符,具有右结合性。 其功能是对参与运算的数的各二进位按位求反。例如~9的运算为: ~(0000000000001001)结果为:1111111111110110 5. 左移运算 左移运算符“<<”是双目运算符。其功能把“<< ”左边的运算数的各二进位全部左移若干位,由“<<”右边的数指定移动的位数,
高位丢弃,低位补0。例如: a<<4 指把a的各二进位向左移动4位。如a=00000011(十进制3),左移4位后为00110000(十进制48)。 6. 右移运算 右移运算符“>>”是双目运算符。其功能是把“>> ”左边的运算数的各二进位全部右移若干位,“>>”右边的数指定移动的位数。
例如:设 a=15,a>>2 表示把000001111右移为00000011(十进制3)。 应该说明的是,对于有符号数,在右移时,符号位将随同移动。当为正数时, 最高位补0,而为负数时,符号位为1,最高位是补0或是补1 取决于编译系统的规定。Turbo C和很多系统规定为补1。
main(){
unsigned a,b;
printf("input a number: ");
scanf("%d",&a);
b=a>>5;
b=b&15;
printf("a=%d/tb=%d/n",a,b);
}
请再看一例!
main(){
char a='a',b='b';
int p,c,d;
p=a;
p=(p<<8)|b;
d=p&0xff;
c=(p&0xff00)>>8;
printf("a=%d/nb=%d/nc=%d/nd=%d/n",a,b,c,d);
}
二进制 补码 的简便求法: 正的二进制数的补码就是原码。 负的二进制数的补码,符号位为1,其余位为该数绝对值的原码按位取反;然后整个数加1。 (1)、在计算机系统中,数值一律用补码来表示(存储)。 主要原因:使用补码,可以将符号位和其它位统一处理;同时,减法也可按加法来处理。 另外,两个用补 码表示的数相加时,如果最高位(符号位)有进位,则进位被舍弃。 (2)、补码与原码的转换过程几乎是相同的。补码的补码即是原码。
参考:
http://blog.csdn.net/xing_hao/article/details/6677809
http://baike.baidu.com/link?url=q8XiHf_3PZni8FJG_2oZBHoX61Clh7i2eWikfAm-iIeOIYpjB7JhK-a2z2y4nrmNBDYn0razNNiucBBkQeWK_a