{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 tianxia6688 的文章《【计算机视觉】Opencv中的Face Detection using Haar Cascades》','https://www.xiaopingtou.net/article-84126.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
【计算机视觉】Opencv中的Face Detection using Haar Cascades
标签(空格分隔): 【图像处理】声明:引用请注明出处http://blog.csdn.net/lg1259156776/
五种典型的haar-like特征,为何能用来检测人脸,人眼呢?
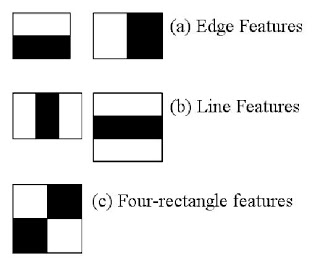 它给出的一个经验之谈是
它给出的一个经验之谈是 1. the region of the eyes is often darker than the region of the nose and cheeks
2. the eyes are darker than the bridge of the nose
但是这样的window在别的地方特征就不明显了,那么如何从160000+的features中选择最好的特征呢:它说采用Adaboost。

We select the features with minimum error rate, which means they are the features that best classifies the face and non-face images.
其实就是adaboost的过程,选择最小错误率的特征,实际上是提高错分图像的权重,然后再进行classification,然后计算新的错误率和新的权重,一直到达到精度或者需要的特征数量足够为止。 所以,最终的分类器实际上是这些弱分类器的加权和,之所以被称之为weak,说的就是它们单独工作可能不能分类,但是一起可以组成较强的分类器。论文中说,甚至200个特征就可以达到95%的精度。 它们最后建立了6000个特征,但是考虑到图像的大部分区域都不是人脸,所以最好还是用一个简单的方法判断是不是人来你,如果不是就直接扔掉,不再对该window进行后续的处理。这样就可以进一步的降低时间消耗。 这种思想真是值得借鉴,因为有点类似TLD中的方差分类器,方差分类器的作用就是通过快速的第一步淘汰掉一半的样本,然后使得进入后续分类器的样本数量减少,有助于提高速率。 利用haar-cascade detection,opencv中可以直接从xml文件中导入训练好的参数,并先进行人脸检测,然后在人脸位置开窗,检测人眼。就这样easy:
import numpy as np
2 import cv2
3
4 face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
5 eye_cascade = cv2.CascadeClassifier('haarcascade_eye.xml')
6
7 img = cv2.imread('sachin.jpg')
8 gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
1 faces = face_cascade.detectMultiScale(gray, 1.3, 5)
2 for (x,y,w,h) in faces:
3 cv2.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2)
4 roi_gray = gray[y:y+h, x:x+w]
5 roi_color = img[y:y+h, x:x+w]
6 eyes = eye_cascade.detectMultiScale(roi_gray)
7 for (ex,ey,ew,eh) in eyes:
8 cv2.rectangle(roi_color,(ex,ey),(ex+ew,ey+eh),(0,255,0),2)
9
10 cv2.imshow('img',img)
11 cv2.waitKey(0)
12 cv2.destroyAllWindows()

2015-11-05 调试记录 张朋艺