{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 bibiboom 的文章《深度学习(六十一)NNPACK 移植与实验》','https://www.xiaopingtou.net/article-84331.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
一、Ubuntu下使用:1、克隆下载NNPACK
需要加入pthread库,否这会报错。4、测试代码
git clone https://github.com/Maratyszcza/NNPACK.git2、安装nijia,并编译Install ninja build systemsudo apt-get install ninja-build || brew install ninjaInstall PeachPy assembler and confu configuration system[sudo] pip install --upgrade git+https://github.com/Maratyszcza/PeachPy
[sudo] pip install --upgrade git+https://github.com/Maratyszcza/confuThen clone NNPACK, install dependencies, configure, and buildcd NNPACK
confu setup
python ./configure.py
ninja3、链接的时候还需要用到pthread库,否在会遇到找不到实现函数。target_link_libraries(NNPACK libnnpack.a libpthreadpool.a pthread)需要加入pthread库,否这会报错。4、测试代码
#include
#include "nnpack.h"
#include
#include
using namespace std;
float test_nnpack(){
//init nnpack
enum nnp_status init_status = nnp_initialize();
if (init_status != nnp_status_success) {
return 0;
}
enum nnp_convolution_algorithm algorithm = nnp_convolution_algorithm_auto;
enum nnp_convolution_transform_strategy strategy=nnp_convolution_transform_strategy_tuple_based;
const size_t batch_size = 1;
const size_t input_channels = 128;
const size_t output_channels = 128;
const struct nnp_padding input_padding = { 1, 1, 1, 1 };
const struct nnp_size input_size ={ 256, 256};
const struct nnp_size kernel_size = { 5, 5 };
const struct nnp_size stride={.width=2,.height=2};
const struct nnp_size output_size = {
.width = (input_padding.left + input_size.width + input_padding.right - kernel_size.width)/stride.width + 1,
.height =(input_padding.top + input_size.height + input_padding.bottom - kernel_size.height)/stride.height + 1
};
//malloc memory for input, kernel, output, bias
float* input = (float*)malloc(batch_size * input_channels *input_size.height *input_size.width * sizeof(float));
float* kernel = (float*)malloc(input_channels * output_channels * kernel_size.height * kernel_size.width * sizeof(float));
float* output = (float*)malloc(batch_size* output_channels * output_size.height * output_size.width * sizeof(float));
float* bias = (float*)malloc(output_channels * sizeof(float));
pthreadpool_t threadpool= nullptr;
struct nnp_profile computation_profile;//use for compute time;
//init input data
int i,j;
for(int c=0; cout;
for(int i=0;i
在mxnet、tiny-dnn中的引用方法:https://www.insight.io/github.com/dmlc/mxnet/blob/master/src/operator/nnpack/nnpack_convolution-inl.hhttps://github.com/tiny-dnn/tiny-dnn/blob/master/tiny_dnn/core/kernels/conv2d_op_nnpack.h在tiny-dnn中,底层调用nnpack为啥只采用了一个线程,于是我测试了多线程的速度,经过测试发现nnpack的弱点,原来在于多线程: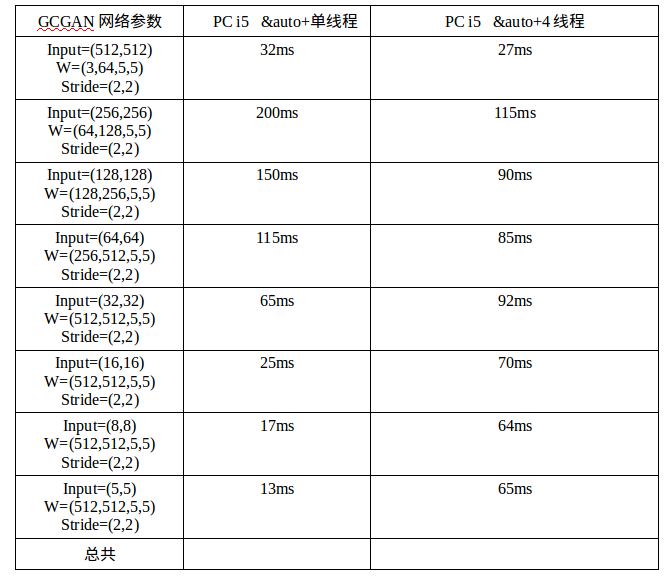
二、android使用1、添加ndk-build环境变量路径:export NDK_ROOT=/home/hjimce/Android/Sdk/ndk-bundle/cd到nnpack所在的目录,更改jni APP_PLATFORM := android-212、直接运行:${NDK_ROOT}/ndk-build 3、代码中引用cmake要指定相关的库文件:arguments "-DANDROID_ARM_NEON=TRUE", "-DANDROID_TOOLCHAIN=clang"
ndk {
// Specifies the ABI configurations of your native
// libraries Gradle should build and package with your APK.
abiFilters 'x86','armeabi-v7a'
}手机速度测试: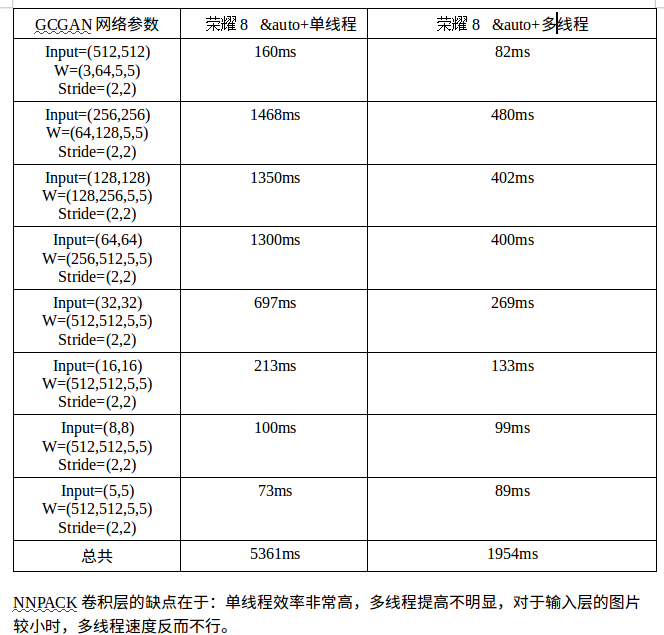
修改:多线程时间测试不能使用time.clock(),可使用auto begin =std::chrono::high_resolution_clock::now();