SIGAI特约作者
Fisher Yu
CV在读博士
研究方向:情感计算
什么是行人重识别(ReID)
如下图,给定一个行人图或行人视频作为查询query,在大规模底库中找出与其最相近的同一ID的行人图或行人视频。
 ReID(Person Re-identification)任务描述[2]
ReID(Person Re-identification)任务描述[2]
为什么需要ReID呢?
因为在安防场景下,跟踪一个目标,只靠人脸识别是不够的,在脸部信息丢失时(罪犯有时把脸特意蒙住一大部分,或者离太远了拍不清脸),行人信息就能辅助跟踪识别。
ReID与人脸识别有什么联系和区别?
都是多媒体内容检索,从方法论来说是通用的;但是ReID相比行人更有挑战,跨摄像头场景下复杂姿态,严重遮挡,多变的光照条件等等。
做ReID的话,一般从两方面入手:
A、特征工程,设计网络来学习不同场景下都general的visual feature,用probe-gallery的特征相关性来作为ranking的依据,一般直接Softmax分类。
B、度量学习,设计损失函数,用多张图像的label来约束它们特征之间的关系,使学到的特征尽量类内间隔短,类间间隔大。
PCB-RPP[1],2017
早期比较经典的文章,方法简洁明了。
main contribution:
1. 提出了均匀分块的 Part-based Convolutional Baseline(PCB),探讨了较优的块间组合方式
2. 提出了基于 parts 的 Refined part pooling(RPP),用注意力机制来对齐 parts
 PCB框架[1]
PCB框架[1]
如上图所示,PCB框架的流程是:
1、对输入384*128行人图提取深度特征(ResNet50),把最后一个block( averagepooling前)的下采样层丢弃掉,得到空间大小 24*8的 tensor T
2、按照水平方向分成均匀分成6parts,即6个空间大小 4*8 tensor,然后各自进行 average pooling,得到6个column vectors g
3、使用1*1卷积对g降维通道数,然后接6个FC层(权值不共享),Softmax进行分类
4、训练时等于有 6个cross-entropy loss;测试时则将 6个 vectors h 合并在一起,再算相似度
这里有几种组合方式和超参可以探讨:
A、Deep feature的空间维度大小?该分成多少parts?
B、把6个column vector h 先 average pooling 成 1个 vector,再 FC 分类?
C、6个FC层之间的权值是否共享?
作者在文中做了实验来对比结果,找到最优的组合方案~~
至于为什么分part的效果会更好,也是基于行人结构分割的先验知识驱使(类似用Pose key point来做一样)。比如part1,能更有针对性地根据头部信息来分类~~
 RPP框架[1]
RPP框架[1]
讲完了PCB,我们来看RPP~
RPP本质上就是个attention module,目标是把6 parts 对应的空间分布进行软权值分配,进而对齐parts(PCB中均匀分割6parts 的过程,其实可看成人为地 hard attention,只把当前part空间权值设为1,其他parts都为0)
如上图所示,RPP思路:
1、把深度特征tensor T 中每个column vectors f 都分为6类(假设共有6个parts),文中是通过线性函数加Softmax来实现(其实就类似用1*1卷积来作segmentation一样)

2、把每个part对应的attention map 权值叠加回 tensor T 里(即上图的 GAP过程),得到各 part 的spatial 空间压缩后的 feature vector g ~ 后续步骤都和PCB一样~
PCB-RPP训练流程:
 PCB-RPP训练流程[1]
PCB-RPP训练流程[1]
文中为了保证学到的是part based attention map来对齐parts,故特意在预训练完PCB后,在Step3处先fix住PCB里所有层的参数,单独训练 part classifier。如下图所示,如果不加Step 3的限制,出来的6个attention map 将很随机,性能也会下降。
 attention map[1]下图是加了Step3的效果
attention map[1]下图是加了Step3的效果
从实验结果看,加了RPP对MAP提升还是很大的:
 Results[1]
Results[1]
总结:
文中PCB的思想虽然简单,但是后续CVPR2018中各种part-based ReID文章(各种 Multi-scale, multi-level part fusion 啥的)提供了参考价值。特别是云从科技的这篇MGN[2],更是将各种粒度的parts 和 triplet loss+ Softmax loss玩得淋漓尽致~
SGGNN [3],ECCV2018
说完了ReID的单张图像part based特征工程,我们来谈谈多张图像输入的 metric learning方法,传统的contrastive loss, triplet loss 和 quadruplet Loss就不介绍了,下面说说基于图模型的 SGGNN。
Similarity-Guided Graph Neural Network (SGGNN) 主要贡献是:
1、网络的输入是probe和多个gallery,通过 GNN 来fuse不同probe-gallery pairs的差异性特征;而不像传统方法probe与每个gallery间都是单独计算 similarity
2、Similarity-Guided。图神经网络中节点与节点间的 edge weights 不是直接通过节点间的非线性函数(无监督) 得到,而是利用gallery的标签,有监督地计算 gallery-gallery similarity得到。
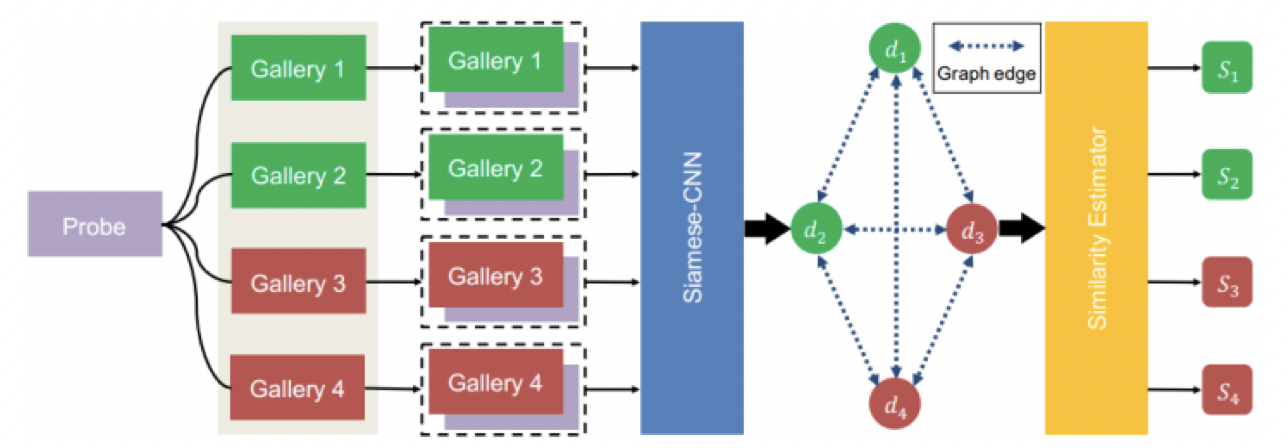 SGGNN整体框架[3]
SGGNN整体框架[3]
如上图所示,假定输入是一个probe和四个gallery,首先每对probe-gallery 都经过Siamese-CNN 来计算关系特征di,作为GNN中的节点node;而node间的edge weights可通过 gallery-gallery pair过相同的Siamese-CNN来得到;接着根据图网络中d1,d2,d3,d4及权值关系,来更新节点的关系特征,作为similarity score(即Sigmoid后的二分类)。
那问题来了,如何设计网络来提取di?
又如何设计GNN来更新节点值呢?
 节点输入特征生成[3]
节点输入特征生成[3]
如上图所示,提取di很简单,就是把图像对送进参数共享的ResNet50,出来的 deep feature进行 element-wise相减,接着element-wise square然后 BN,得到di;若要继续算图像对similarity的话,后接个FC层然后Sigmoid即可。
 节点特征更新[3]
节点特征更新[3]
上图所示,目标就是更新di特征。虽然不太懂为啥专门用2个FC层搞了个message network 来映射di到ti,文中说这样可以增强节点间流动的信息,但估计增加不少运量和额外参数。Anyway我们已经得到了各个节点增强后的message+各个edge weights+原始的di特征,按照下面的公式更新di特征即可:

for i=1,2,...N
至此,整个网络就可以端到端地去训练了,通过probe-gallery label 的 cross-entropy loss引导di更新,又通过gallery-gallery label 的 cross-entropy loss引导 edge weights 更新(后者不确定是否一定需要,文中也没细讲)。
关于利用gallery-gallery相似分值来引导改善probe-gallery关系特征,文中举了一个类似metric learning的例子很有趣:给定 probe p 和 gallery gi 和 gj,假定 (p, gi) 是 hard positive pair node,而 (p, gj) 和 (gi, gj) 都是相对 easy positive pairs node。如果节点间没有信息流动,(p, gi)的相似分值不可能很高。但如果使用 (gi, gj) 相似度来引导更新(p, gi)的关系特征,那么(p, gi)的相似分值可能会高。
从实验结果看,使用Similarity-guided确实对性能提升很大:
 results[3]
results[3]
总结与展望:
SGGNN使用gallery-gallery引导多个probe-gallery进行特征融合,确实能让网络学到更discriminant特征。哈哈,估计有人会想把PCB中Part based feature和SGGNN融合起来用了,或者把parts当成节点来用了~~
Reference:
[1] Yifan Sun, Beyond Part Models: Person Retrieval with Refined Part Pooling
[2]Guanshuo Wang, Learning Discriminative Features with Multiple Granularity
for Person Re-Identification
[3]Yantao Shen, Person Re-identification with Deep Similarity-Guided Graph Neural Network,ECCV2018
{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 z735640642 的文章《行人重识别 PCB-RPP,SGGNN》','https://www.xiaopingtou.net/article-90365.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}