进程—进程调度(1)
上下文切换
进程可以调度,但必须保证每个进程都可以顺序的执行,而一个进程执行所需的全部信息可由进程的PCB(task_struct)维护,所以在进程发生切换的时候可以将当前进程的运行状态信息(快照)保存到它的PCB中(这样就能在下一次调度程序选择到它时接着上一状态继续执行),将马上要执行的进程的运行状态信息(在PCB中)恢复,这样就可以合理的完成调度,这个过程就叫上下文切换。
中断
上下文切换是在内核中完成的,对用户透明,所以在上下文切换的时候必须先陷入内核(一般是通过时钟中断和系统调用)。上下文的切换需要硬件的支持。当前进程正在运行,当中断发生时,中断硬件 将程序计数器、程序状态字、有时还有一个或多个寄存器(进程的运行状态信息)压入当前进程的内核堆栈 中,PC随即跳转到中断服务程序 入口(根据硬件向量法或软件查询法得到中断服务程序入口地址)去执行中断服务程序。注意,这些工作都是硬件完成的,在这些工作完成的同时完成了一次堆栈切换 (从进程的用户堆栈 切换到进程的内核堆栈 ,由中断硬件完成)。然后,PC的控制权转移到了软件 (中断服务程序),一般地,中断服务程序有一个自己的中断堆栈 (就像进程有自己的内核堆栈一样),为了不破坏内核堆栈,在执行中断服务程序的过程中又会发生一次堆栈切换(从内核堆栈切换到中断堆栈,这次的切换是软件完成的),进入到中断上下文 之中,随后中断服务程序会调用处理特定中断请求的中断处理例程 ,让中断处理例程运行在中断上下文之中。中断处理例程完成中断处理之后返回到中断服务程序,返回的过程又会涉及到一次堆栈切换(由中断堆栈切换到内核堆栈,这次的切换也是软件完成的),最后,中断服务程序执行中断返回 指令,由中断硬件将内核堆栈中的状态信息恢复到相应的寄存器中,在恢复寄存器的同时清空内核堆栈中保存的状态信息,系统从内核态返回到用户态,这里又发生了一次堆栈切换(从内核堆栈切换到用户堆栈,由中断硬件完成)。
发生上下文切换的中断过程
中断服务程序调用中断处理例程,中断处理例程在执行的过程中调用了调度程序 进行调度,这时,调度程序会检查是否需要发生上下文切换(不是每次中断都会发生上下文的切换,例如某个时钟中断就可能不会导致上下文切换),发现需要发生上下文切换。接下来,要完成不同进程之间的内核栈的切换。为什么要切换内核栈呢?因为restore_all需要从内核栈中恢复中断现场,每个进程都有一个内核堆栈,它们互不相同,里面保存了各自的中断现场,所以要想恢复进程A的中断现场就得先切换到进程A的内核堆栈中去。
参考《Linux内核代码情景分析》第三章
ENTRY(ret_from_intr)
...
jne ret_with_reschedule
...
ret_with_reschedule:
cmpl $0 ,need_resched(%ebx)
jne reschedule
cmpl $0 ,sigpending(%ebx)
jne signal_return
restore_all:
RESTORE_ALL
reschedule:
call SYMBOL_NAME(schedule)
...
jmp ret_from_intr
#define RESTORE_ALL
popl %ebx;
popl %ecx;
popl %edx;
popl %esi;
popl %edi;
popl %ebp;
popl %eax;
1 : popl %ds;
2 : popl %es;
addl $4 ,%esp;
3 : iret;
内核堆栈的切换由内联汇编代码switch_to 完成。
参考《深入理解Linux内核》中文第三版.第三章和第七章
static inline
task_t * context_switch(runqueue_t *rq, task_t *prev, task_t *next)
{
struct mm_struct *mm = next->mm;
struct mm_struct *oldmm = prev->active_mm;
if (unlikely(!mm)) {
next->active_mm = oldmm;
atomic_inc(&oldmm->mm_count);
enter_lazy_tlb(oldmm, next);
} else
switch_mm(oldmm, mm, next);
...
switch_to(prev, next, prev);
return prev;
}
#define switch_to(prev,next,last) do {
unsigned long esi,edi;
asm volatile ("pushfl
"
"pushl %%ebp
"
"movl %%esp,%0
"
"movl %5,%%esp
"
"movl $1f,%1
"
"pushl %6
"
"jmp __switch_to
"
"1: "
"popl %%ebp
"
"popfl"
:"=m" (prev->thread.esp),"=m" (prev->thread.eip),
"=a" (last),"=S" (esi),"=D" (edi)
:"m" (next->thread.esp),"m" (next->thread.eip),
"2" (prev), "d" (next));
} while (0 )
struct task_struct fastcall * __switch_to(struct task_struct *prev_p, struct task_struct *next_p)
{
struct thread_struct *prev = &prev_p->thread,
*next = &next_p->thread;
int cpu = smp_processor_id();
struct tss_struct *tss = &per_cpu(init_tss, cpu);
__unlazy_fpu(prev_p);
load_esp0(tss, next);
load_TLS(next, cpu);
asm volatile ("movl %%fs,%0" :"=m" (*(int *)&prev->fs));
asm volatile ("movl %%gs,%0" :"=m" (*(int *)&prev->gs));
if (unlikely(prev->fs | prev->gs | next->fs | next->gs)) {
loadsegment(fs, next->fs);
loadsegment(gs, next->gs);
}
if (unlikely(next->debugreg[7 ])) {
loaddebug(next, 0 );
loaddebug(next, 1 );
loaddebug(next, 2 );
loaddebug(next, 3 );
loaddebug(next, 6 );
loaddebug(next, 7 );
}
if (unlikely(prev->io_bitmap_ptr || next->io_bitmap_ptr))
handle_io_bitmap(next, tss);
return prev_p;
}
switch_to(prev,next,last)并不是一个函数,只是一个宏定义,现在我把它放到调度函数的环境下:
asmlinkage void __sched schedule(void )
{
task_t *prev, *next;
runqueue_t *rq;
···
prev = context_switch(rq, prev, next);
barrier();
finish_task_switch(prev);
···
prev = current;
···
}
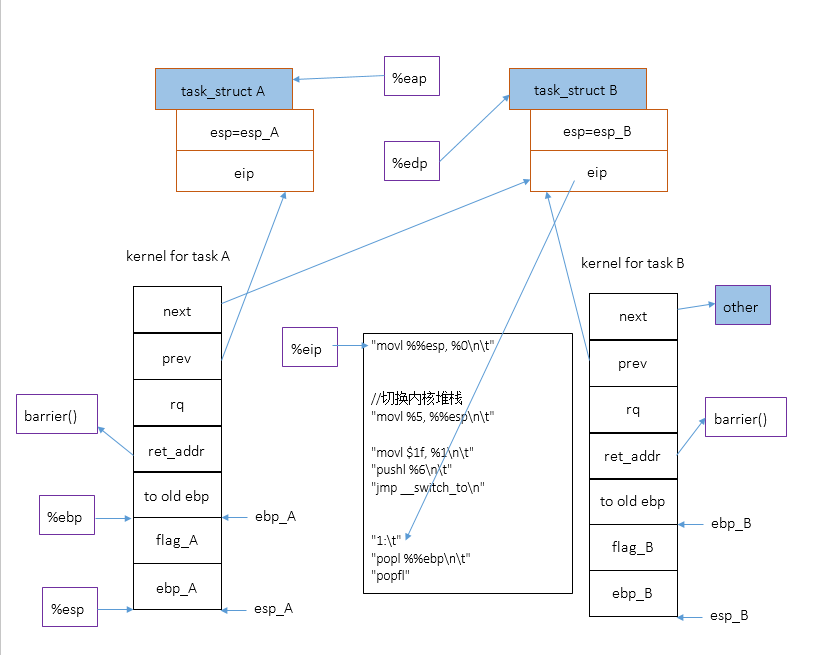
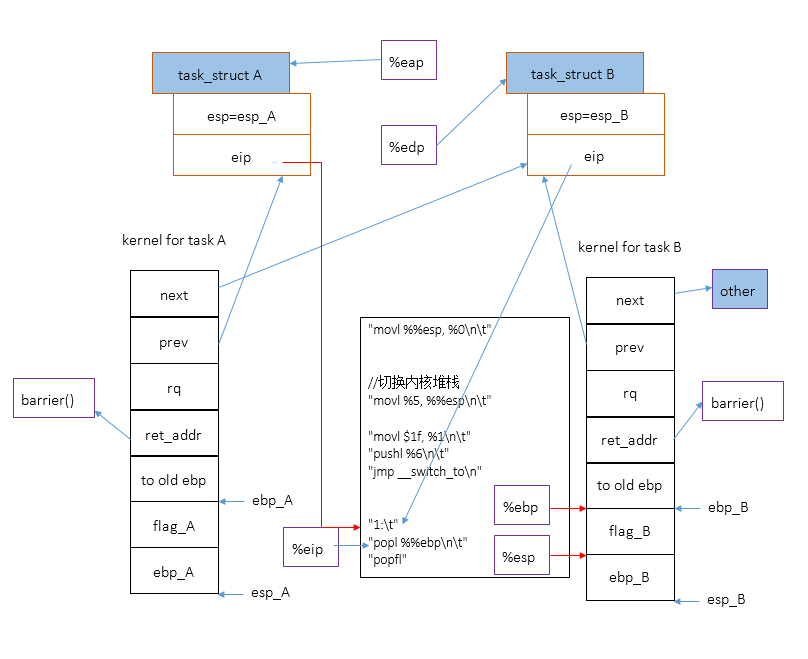
图示:
方框中的%x表示寄存器,进程A是prev,进程B是next。图中%eap是指%eax,%edp是指%edx,标注错了。
下图是cpu刚执行完eip所指的指令movl %%esp, %0
后的情况,注意,我忽略了堆栈中的局部变量unsigned long esi,edi;,movl %%esp, %0
表示:ebp_A==> A->thread.esp
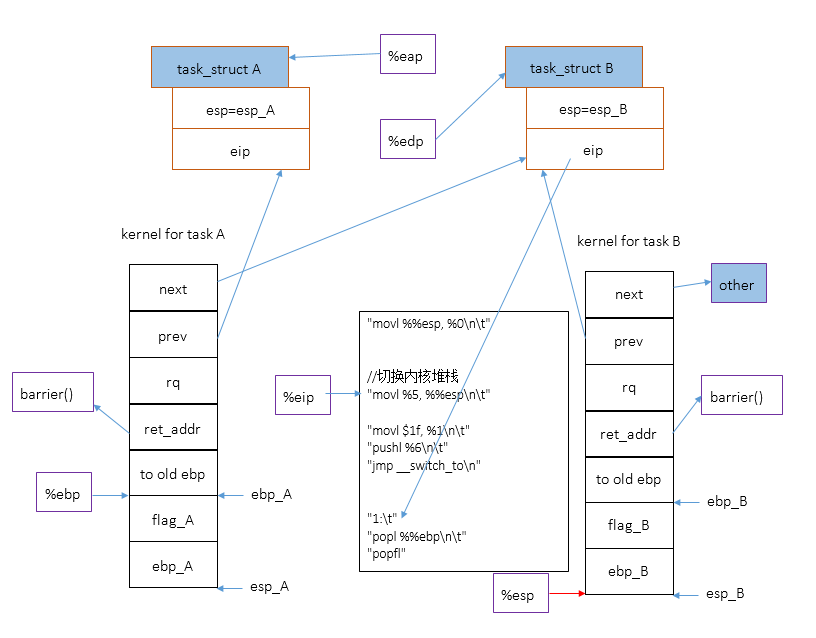
下图展示了切换内核堆栈之后的情况。注意,这时候cpu用来索引局部变量的寄存器%ebp还没有切换到B的内核堆栈,所以代码中对局部变量的引用仍然来自A的内核堆栈。
切换堆栈之后,将1赋值到A->thread.eip。
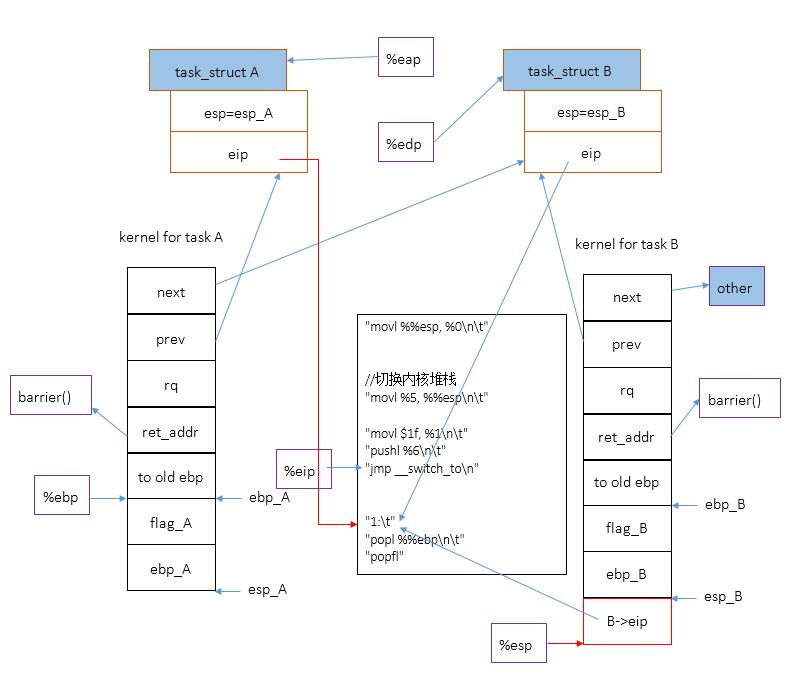
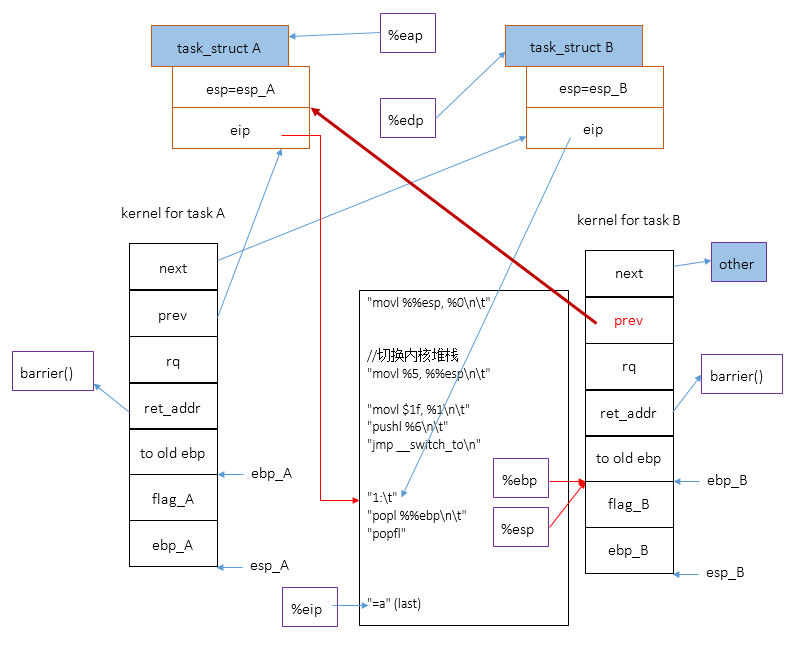
注意,函数__switch_to不是通过call指令调用的,而是直接jmp过去的。所以不会在B的内核堆栈中构造返回地址,不过,cpu执行pushl %6
指令时将一个保存在B中的指令地址B->thread.eip压入了B的内核堆栈中,这相当于手动为__switch_to构造了一个返回地址,所以在__switch_to返回时[ret],cpu会调转到B->thread.eip处执行,即跳转到1处。
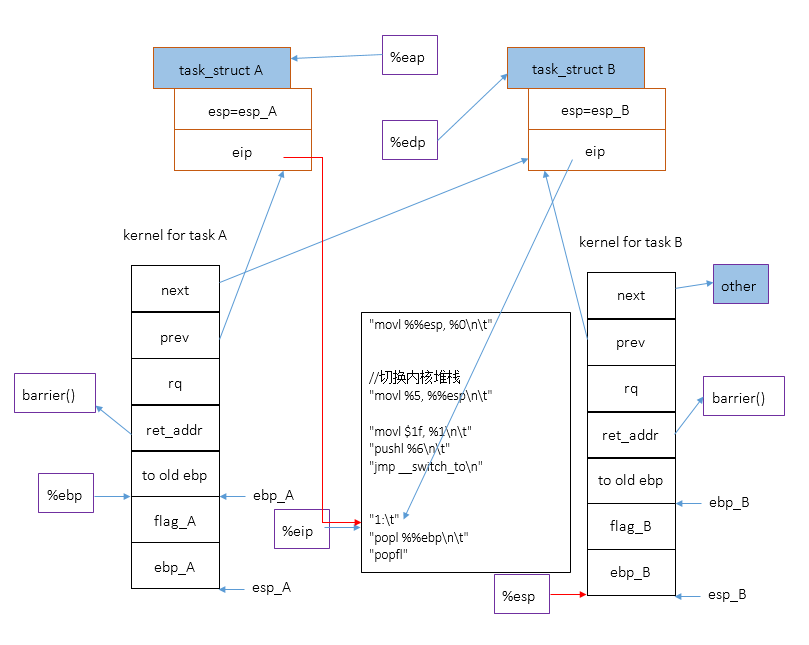
执行指令popl %%ebp
,切换%ebp寄存器到B内核堆栈:ebp_B==>%ebp
最后更改B内核堆栈中的局部变量prev的值,使之指向A。因为%ebp已经切换到B的内核堆栈上了,所以对局部变量last【宏名称,预处理阶段会被替换成prev】的引用会更改B内核堆栈中的局部变量prev的值。
通过上面一系列的过程,内核完成将内核堆栈由A[prev]切换到B[next]的工作,而且,现在,B通过current宏能够获得自己的task_struct,同时拥有到A的task_struct的引用prev[B内核堆栈中的局部变量prev]。
那为什么将A调度出去了还要在B中拥有对A的引用呢?
因为在流程回到schedule之后,虽然控制流掌握在了B的手中,但是在B返回用户态之前,内核在schedule的后续工作中还得用到A的task_struct。
内核还需要调用函数finish_task_switch(prev)对进程A进行后续地处理。
最后,schedule的任务完成,返回到 call SYMBOL_NAME(schedule)的下一条指令接着执行,内核堆栈恢复到调用schedule之前的状态。最终,内核执行到restore_all,恢复中断现场,进程B返回到被中断之前的状态,在用户态接着执行,仿佛从未发生过中断一样。
Linux进程类别
1.实时进程:高优先级,响应快,优先级范围[0,99]。
Linux中与调度相关的系统调用
系统调用
说明
nice()
改变一个普通进程的静态优先级
getpriority()
获得一组普通进程的最大静态优先级
setpriority()
设置一组普通进程的静态优先级
sched_getscheduler()
获得一个进程的调度策略
sched_setscheduler()
设定一个进程的调度策略和实时优先级
sched_getparam()
获得一个进程的实时优先级
sched_setparam()
设置一个进程的实时优先级
sched_yield()
自愿放弃处理器而不阻塞
sched_get_priority_min()
获得一种策略的最小实时优先级
sched_rr_get_interval()
获得时间片轮转策略的时间片值
sched_setaffinity()
设置进程的CPU亲和力掩码
sched_getaffinity()
获得进程的CPU亲和力掩码
几个优先级字段 nice
static_prio
nice和static_prio是普通进程会用到的两个优先级字段,用轮转策略的实时进程也会用到它们,只是用来重新计算轮转时间片长度。
rt_priority
rt_priority是实时进程用到的优先级字段。
prio
这才是决定进程调度优先级的字段,也就是说,进程在哪个就绪队列中由这个字段决定。
Linux进程调度策略
用户可以调用系统调用sched_setscheduler()设置调度策略。
unsigned int policy;
Linux的进程调度是抢占式的,允许高优先级进程抢占低优先级进程,这是下面几个调度策略对应的算法都必须确保的基本机制。另外,调度只会发生在位于就绪队列中的进程之间(ranqueue)。
实时进程 的调度优先级只由实时优先级(rt_priority,范围为[0,MAX_RT_PRIO-1])静态的决定,从一开始由用户指定后,就不再动态地改变,不受nice值的影响(nice值只影响调度优先级在[100,139]范围内的普通进程的调度优先级)。实时优先级的调度优先级(prio)通过其实时优先级(rt_priority)计算(prio = MAX_RT_PRIO-1 - rt_priority)得到,范围在0~MAX_RT_PRIO-1间。默认MAX_RT_PRIO为100,所以默认的实时进程的调度优先级(prio)范围是[0,99],实时进程的调度优先级虽然不会自己动态的改变,但是可以由用户使用系统调用sched_setparam()和sched_setscheduler()来重新设置它的实时优先级,进而改变调度优先级。实时进程位于高优先级队列(明确地说,优先权在[0~MAX_RT_PRIO-1]区间内的优先级队列)中,而且总是位于活动运行队列中,所以只要有实时进程存在,普通进程永远也别想运行。
普通进程 的调度优先级根据静态优先级static_prio和平均睡眠时间sleep_avg动态的来计算,static_prio是根据nice值得到的,两者可以相互转换。详细的说明请见task_struct代码注释。默认的普通进程的调度优先级(prio)范围是[100,139]。
1.
SCHED_FIFO
值为1-实时进程-用基于优先权的先进先出算法。基于SCHED_FIFO调度机制的实时进程在运行时会一直占用CPU,除非就绪队列中有优先级更高的实时进程,或自愿调用阻塞原语(如sleep_on_interruptible()),或停止,或被杀死,或通过调用sched_yield()自动放弃CPU。
2.
SCHED_RR
值为2-实时进程-用基于优先权的轮转法。一旦当前进程自愿调用阻塞原语(如sleep_on_interruptible()),或停止,或被杀死,或通过调用sched_yield()自动放弃CPU或一个时间片消耗完毕,或就绪队列中有优先级更高的实时进程,则会在中断返回时发生调度。基于SCHED_RR调度机制的调度程序将该进程置于同优先级队列的末尾,然后运行该优先级队列中的下一个实时进程。这是分时系统实现良好交互性的基础算法,又名时间片轮转调度算法。
3.
SCHED_NORMAL
值为0-非实时进程-用基于优先权的多级反馈队列轮转法,根据进程过去的执行情况动态的调整调度优先级,一般还会将执行完轮转时间片的进程放入过期可运行队列中。兼顾了作业的周转时间和交互性,并且防止了饿死。
普通进程的调度策略:SCHED_NORMAL
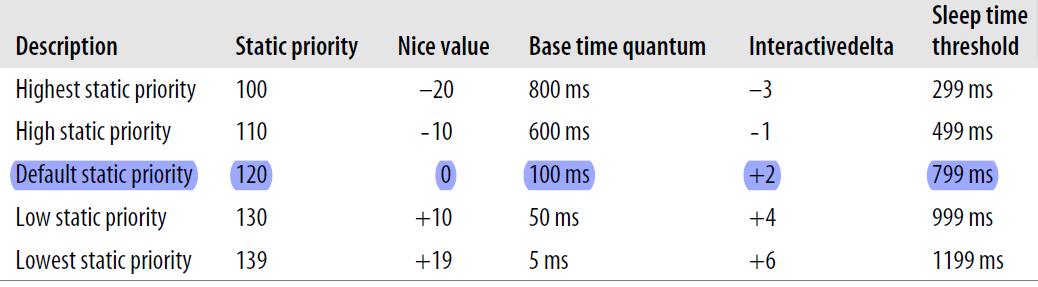
普通进程的调度优先级(prio)由2个因素决定,一个是进程的静态优先级(static_prio,又叫基本优先级,默认值是120),另一个是进程的平均睡眠时间(sleep_avg)。static_prio的范围为[100,139],新进程总是继承其父进程的静态优先级。
static_prio
static_prio通过nice(范围为[-20,19])计算得到(static_prio = 120 + nice),所以用户可以通过系统调用nice()和setpriority()来设置nice值进而改变自己拥有的进程的静态优先级(也只能通过这两个系统调用改变静态优先级,否则静态优先级不会发生变化,尽管动态优先级会发生变化)。
普通进程每次执行的时候都有一个有限的轮转时间片,这是进程在被抢占前能够连续占用CPU的时间片长度,如果没有高优先级进程抢断,当前进程会可以一直占用CPU直到用完它的轮转时间片。静态优先级 用来计算普通进程的轮转时间片,基本规则是静态优先级越高,static_prio越小,轮转时间片越长。所以对于普通进程,静态优先级越高的进程获得的连续执行CPU的时间片越长,也可以说nice值唯一决定了普通进程能获得的轮转时间片长度。具体的计算规则可以参考../kernel/sched.c 中的task_timeslice(),这个函数计算并返回一个进程轮转时间片长度,或者参考《深入理解Linux内核》第七章中普通进程的调度章节下的基本时间片一节。
prio
task_struct中的这个字段是进程的调度优先级,用来决定进程在哪个优先级队列中,进而实现O(1)调度。对于普通进程,这个字段被称为它的动态优先级 ,通过静态优先级和平均睡眠时间计算得到,范围是[100,139]。
普通进程的调度策略(SCHED_NORMAL)的主要思想是通过进程过去的执行情况来衡量这个进程是属于I/O消耗型还是CPU消耗型,具体的衡量指标是一个进程的平均睡眠时间sleep_avg。如果一个进程的sleep_avg大,则该进程更加趋向于I/O消耗型,优先级就越高,prio就越小。
动态优先级: prio = max (100, min (static_prio - bonus,139) )
bonus = 10*sleep_avg/HZ - 5,范围在[-5,5]之间。(sleep_avg 范围为[0,HZ]),所以sleep_avg = HZ/2 时,进程调度优先级保持不变;当HZ > sleep_avg > HZ/2 时,进程调度优先级会提高;当0 < sleep_avg < HZ/2 时,进程调度优先级会降低。
对于交互性强的进程,它不会一次性的就将轮转时间片给用光(这一般是CPU消耗型进程干的事),而是用一小会儿之后,进行一次I/O操作,放弃掉CPU,这使得它可以长时间的位于活期可执行队列中,不至于用完时间片了就被重新计算时间片,然后放到过期可执行队列中,久久得不到执行机会。而且经常性的执行I/O操作正是交互型进程的一大特点,这也是交互型进程之所以为交换型进程的根本原因,系统给予这种进程以较高的bonus,使其调度优先级更高,有更多的被调度的机会。
实时进程的调度策略
参考task_struct代码注释和Linux进程调度策略的前言部分。
进程调度时机
调度时机来临时,内核或驱动将调用schedule(),在Linux中调度的时机主要有:
计算调度优先级:effective_prio(p)
计算进程p的调度优先级,在更新进程调度优先级时会被recalc_task_prio()调用。
static int effective_prio(task_t *p)
{
int bonus, prio;
if (rt_task(p))
return p->prio;
bonus = CURRENT_BONUS(p) - MAX_BONUS / 2 ;
prio = p->static_prio - bonus;
if (prio < MAX_RT_PRIO)
prio = MAX_RT_PRIO;
if (prio > MAX_PRIO-1 )
prio = MAX_PRIO-1 ;
return prio;
}
#define MAX_USER_RT_PRIO 100
#define MAX_RT_PRIO MAX_USER_RT_PRIO
#define MAX_PRIO (MAX_RT_PRIO + 40)
#define rt_task(p) (unlikely((p)->prio < MAX_RT_PRIO))
#define USER_PRIO(p) ((p)-MAX_RT_PRIO)
#define MAX_USER_PRIO (USER_PRIO(MAX_PRIO))
#define PRIO_BONUS_RATIO 25
#define MAX_BONUS (MAX_USER_PRIO * PRIO_BONUS_RATIO / 100)
#define DEF_TIMESLICE (100 * HZ / 1000)
#define MAX_SLEEP_AVG (DEF_TIMESLICE * MAX_BONUS)
#define NS_TO_JIFFIES(TIME) ((TIME) / (1000000000 / HZ))
#define MAX_SLEEP_AVG (DEF_TIMESLICE * MAX_BONUS)
#define CURRENT_BONUS(p)
(NS_TO_JIFFIES((p)->sleep_avg) * MAX_BONUS /
MAX_SLEEP_AVG)
参考
task_struct
long nice;
int static_prio;
unsigned int rt_priority;
int prio;
unsigned long sleep_avg;
unsigned long long timestamp;
unsigned long long last_ran;
cputime_t utime;
cputime_t stime;
unsigned long sleep_time;
unsigned int time_slice;
unsigned int first_time_slice;
const struct sched_class *sched_class;
struct sched_entity se;
struct sched_rt_entity rt;
#ifdef CONFIG_PREEMPT_NOTIFIERS
struct hlist_head preempt_notifiers;
#endif
#if defined(CONFIG_SCHEDSTATS)||define(CONFIG_TASK_DELAY_ACCT)
unsigned int policy;
struct sched_info sched_info;
#endif
struct list_head tasks;
volatile long need_resched;
struct list_head run_list;
prio_array_t *array ;
cpumask_t cpus_allowed
struct thread_info *thread_info;
archi386kernelentry.s # system call handler stub
ENTRY(system_call)
pushl %eax # save orig_eax
SAVE_ALL
GET_THREAD_INFO(%ebp)
# system call tracing in operation
testb $(_TIF_SYSCALL_TRACE|_TIF_SYSCALL_AUDIT),TI_flags(%ebp)
jnz syscall_trace_entry
cmpl $(nr_syscalls), %eax
jae syscall_badsys
syscall_call:
call *sys_call_table(,%eax,4 )
movl %eax,EAX(%esp) # store the return value
syscall_exit:
cli # make sure we don't miss an interrupt
# setting need_resched or sigpending
# between sampling and the iret
movl TI_flags(%ebp), %ecx
testw $_TIF_ALLWORK_MASK, %cx # current->work
jne syscall_exit_work
restore_all:
RESTORE_ALL
{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 再见亦或不见 的文章《进程—进程调度(1)》','https://www.xiaopingtou.net/article-93616.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}