{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 Geekjin 的文章《Linux进程管理》','https://www.xiaopingtou.net/article-94132.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
进程和线程
从操作系统角度来看,进程是资源分配的基本单位,线程是调度的基本单位。进程有独立的地址空间,线程共享进程的内存地址空间。内核通过进程控制块PCB来维护进程相关信息。Linux内核的PCB是task_struct结构体。- 进程控制块PCB
struct task_struct {
pid_t pid;
struct mm_struct *mm;
/* Filesystem information: */
struct fs_struct *fs;
/* Open file information: */
struct files_struct *files;
/* Signal handlers: */
struct signal_struct *signal;
...
};
系统的资源有限
- 查看系统的pid上限
$cat /proc/sys/kernel/pid_max
131072
- fork炸弹
:(){:|:&};:
fork炸弹通过管道创建子进程,进程数量指数级增长,进程表饱和后就无法创建新的进程,直到进程表中的某一进程终止,但是fork炸弹进程会竞争创建新的fork炸弹进程,最后基本不能运行新的进程。forK炸弹会占用大量的CPU和内存,导致系统响应速度骤降。
进程生命周期
- 就绪 进程已经分配到除CPU之外的所有必要资源,只要获得CPU资源便可以执行。
- 运行 进程已经获得CPU资源,进程正在处理机上执行。
- 浅度睡眠 进程处于睡眠状态,正在等待资源的分配,可以被信号唤醒。
- 深度睡眠
进程处于睡眠状态,正在等待资源的分配,但不可以被信号唤醒。
进程在执行过程中,没有命中代码段,此时会发生page fault,进程进入深度睡眠。
- 停止
进程已经停止执行,接收到SIGSTOP和SIGTSTP等信号时,进程进入停止状态,直到收到SIGCONT信号后,进程再次变得可运行。
cpulimit 原理在于通过周期发送SIGSTOP和SIGCONT来控制CPU使用率
- 僵尸 进程已经终止,资源已经释放,但task_struct还在,等待父进程收集的统计信息。
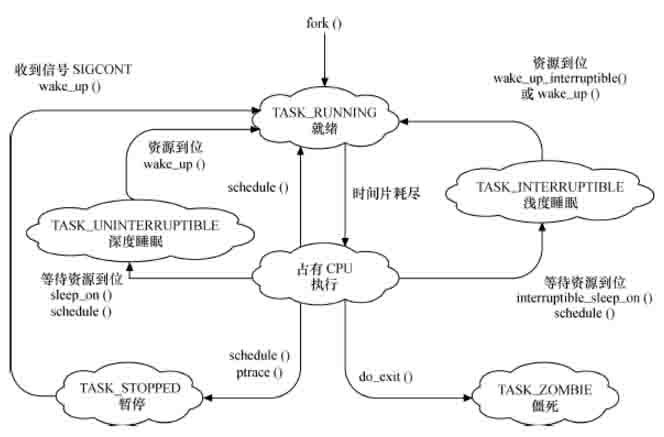
进程,线程的创建
fork, vfork, clone
- fork
pid_t fork(void);
fork创建子进程,父进程返回子进程的PID,子进程返回值为0,fork错误则返回负值。系统为子进程新建task_struct,子进程的task_struct除了pid,ppid之外,继承了父进程task_struct的大部分内容。子进程基本上是父进程的一个副本,包括真实有效的UID,GID,进程组和会话ID,环境,资源打开的文件,共享的进程段。但注意的是,子进程没有继承父进程的超时设置,父进程的文件锁,未决信号。当父进程或子进程对资源进行任何修改,资源就会发生分裂,发生写时拷贝。例如chroot, memory, mmap。
- vfork
pid_t vfork(void);
vfork也是用来创建子进程,vfork和fork的不同之处在于vfork的父进程会被阻塞,子进程exit或调用exec之后,父进程才被调度运行。vfork子进程和父进程共享数据段,子进程的对虚拟地址空间任何修改都对父进程可见。从进程控制块来看,子进程和父进程共享task_struct中的 mm_struct。vfork最初是因为fork没有实现COW机制而出现,fork的COW需要内存管理单元MMU的支持。
- clone
int clone(int (*fn)(void *), void *child_stack,
int flags, void *arg, ...
/* pid_t *ptid, struct user_desc *tls, pid_t *ctid */ );
clone是linux为了创建线程设计的,可以有选择性的继承父进程的资源。clone创建出来的和父进程共享所有资源,那么创建出来的就是线程。clone也可以将创建出来的进程变成父进程的兄弟进程。
写时拷贝技术Copy-On-Write
fork前,数据段的页表权限是读写(R+W)。fork之后,系统将数据段的页表权限设置为只读权限(RD-ONLY),所以父进程和子进程看到的虚拟地址和物理地址是一样的。无论子进程还是父进程对RD-ONLY的页表进行写操作,CPU都会收到一个缺页中断(page fault). 这个时候CPU去申请一新的物理页框(page),把原来的页框数据拷贝到新的物理页框,并且把原来的数据段的页表权限设置为读写(R+W)。这样就完成了COW,父进程和子进程的相同虚拟地址所多对应的物理地址并不一样。 fork后COW前后变化的情况如下:调度器
调度器设计有两个目标,一个是高吞吐率和快响应。追求高吞吐率,必然要求做更多的有用功,而不是频繁的在频繁切换上下文上浪费时间。要求快响应,势必要求更高优先级进程能随时抢到CPU,但抢占会引起上下文切换,上下文切换会引起大量的cache miss。因此,为了响应快就需要抢占,抢占了就会导致吞吐率下降。调度器需要在两者之间做一个平衡。Linux 2.6早期的O(1)调度
#define MAX_USER_RT_PRIO 100
#define MAX_RT_PRIO MAX_USER_RT_PRIO
#define MAX_PRIO (MAX_RT_PRIO + 40)
typedef struct prio_array prio_array_t;
struct prio_array {
unsigned int nr_active; //本进程中进程的个数
unsigned long bitmap[BITMAP_SIZE]; //进程队列queue[MAX_PRIO]的索引位图
struct list_head queue[MAX_PRIO]; //各个优先级所对应的队列
};
O(1)算法的核心数据结构是优先级数组,MAX_PRIO的最大取值为140,因此进程的优先级最大值为139,但优先级的值越小,表示优先级越高。实时进程使用0到99的优先级,普通进程的优先级为100到139。queue数组中包含140个可运行的进程链表,相同优先级的进程被放到queue[prio]的链表中。当某个优先级的进程处于可运行状态时,bitmap中该优先级所对应的位就被置1。因此通过查找bitmap中第一个被置1的位就能达到O(1)找出最高优先级进程。
- 实时进程
- 普通进程
CFS调度算法
从Linux2.6.23内核开始采用CFS(completely fair schedule)调度算法。CFS最求的是CPU资源的公平分配,为了实现公平调度,内核给每个进程维护了一个虚拟运行时间vruntime。
Virtual runtime = (实际运行时间) * 1024/weight
其中nice值越小,weight越大,因此优先级高的进程vruntime增加得慢。调度实体被系统用红黑树组织起来,key为进程的vruntime。红黑树左边节点的vruntime小于右边节点的vruntime,如果进程得到执行,就会开启对vruntime的跟踪,在tick中断到来前更新vruntime,从而调度器可以不断的检查目前系统的公平性。CFS选择vruntime最小的进程来调度(如下图),因此总是选择最左边的节点做为下一个获得CPU的任务,读取操作的时间复杂度为O(LgN)。
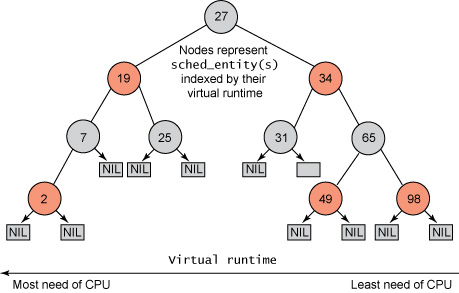
- 调度延迟 对于两个vruntime差不多的进程,可能每个tick都会导致这两个进程的相互切换。例如A进程运行一个tick后,vruntime大于B,于是切换到B进程。B进程运行一个tick后,vruntime又超过了A进程,于是又切换回A进程,如此反复。 为了权衡公平与性能,CFS引入了调度延迟的概念。
- CFS模块化
不同的进程可以选择不同的调度模块。如实时进程使用实时调度模块,普通进程则使用CFS调度模块。
- CFS组调度
chrt和renice
- 设置实时进程调度策略
chrt [options] priority command [argument...]
chrt [options] -p [priority] pid
- 设置nice
renice [-n] priority [-g|-p|-u] identifier...
多核下的负载均衡
在SMP环境下,每个CPU有一个run_queue队列。这样做的好处是尽量使进程在同一个CPU上运行,每个CPU上的调度程序只访问自己的run_queue,避免了竞争。但这样也造成了一些CPU闲着,一些CPU忙不过来的情况,负载均衡需要做的是,在一定的时机下,将进程从一个run_queue迁移到另一个run_queue上,来保持CPU之间的负载均衡。- 实时进程 实时进程严格按照优先级来进行,N个CPU上运行必须是优先级最高的TOP-N个进程。如果TOP-N个进程中,有一个离开TASK_RUNNING状态或者因为优先级被调低而退出TOP-N,那么N+1优先级的进程度就会被调入TOP-N。内核遍历所有的run_queue,把这个N+1优先级进程找出来。如果一个TOP-N之外的实时进程的优先级被调高,内核需要遍历所有run_queue,将优先级处于TOP-N的进程找出来,将正在占用CPU让给新进的TOP-N进程。新进TOP-N进程和退出TOP-N进程可能并不处于同一个CPU上,在运行之前,内核需要将其迁移到退出TOP-N进程上。内核通过pull_rt_task和push_rt_task两个函数来实现实时进程的迁移.
- 普通进程 普通进程并不严格要求优先级关系,可以容忍一定程度的不均衡,所以普通进程的负载均衡可以采用一些一部调整策略。 当前进程离开TASK_RUNNING状态,多对应的run_queue已经没有进程可用是,触发负载均衡,试图从别的run_queue中pull一个进程来运行。每隔一定的时间,启动负载均衡过程,试图解决系统中不均衡。 对于exec的进程,地址空间已经宠爱金,当前CPU上已经不再缓存对它有用的信息,内核也会考虑负载均衡,为他们寻找合适的CPU。
CPU亲和性
CPU软亲和性指的是进程不会在CPU之间频繁迁移。硬亲和性指进程只在指定的CPU上运行。linux的硬亲和性保存在进程task_struct的cpus_allowed这个位掩码标志中,每一位掩码对应一个进程可用的处理器。int pthread_attr_setaffinity_np(pthread_attr_t *, size_t, const cpu_set_t *);
int pthread_attr_getaffinity_np(pthread_attr_t *, size_t, cpu_set_t *);
int sched_setaffinity(pid_t pid, unsigned int cpusetsize, cpu_set_t *mask);
int sched_getaffinity(pid_t pid, unsigned int cpusetsize, cpu_set_t *mask);
taskset设置亲和性
taskset [options] mask command [argument...]
taskset [options] -p [mask] pid
cgroup
cgroups(Control Groups)是Linux内核提供的一种可以限制、记录、隔离进程组(process groups)所使用的物理资源(包括CPU,内存,IO)的机制。cgroups的API以VFS方式实现,用户可以通过文件操作实现cgroups的组织管理。cgroup相关概念
- task: 任务就是系统的一个进程.
- control group: 控制族群是cgroups中的资源控制单位。进程加入控制族群后,进程的资源受到控制族群限制。
- hierarchy: 层级即一棵控制族群树。控制群树上的子节点继承父控制族群的属性。
- subsystem: 子系统就是一个资源控制器。典型的子系统有cpu,cpuacct,cpuset,memory,blkio,devices,net_cls,freezer,ns。
关系
- 子系统必须挂载到一个层级上才能起作用,一个子系统附加到某个层级以后,这个层级上的所有控制族群都受到这个子系统的控制。
- 一个子系统最多只能附加到一个层级。
- 一个层级可以附加多个子系统。
- 进程可以是多个控制族群的成员,但是这些控制族群必须在不同的层级。
cgroups管理cpu资源
cgroups可以用cpu.cfs_period_us和cpu.cfs_quota_us来限制该组中的所有进程在单位时间里可以使用的CPU时间。这里的CFS是完全公平调度器的缩写.。- cpu.cfs_period_us 就是时间周期,默认为 100000,即百毫秒
- cpu.cfs_quota_us 就是在这期间内可使用的 cpu 时间,默认 -1,即无限制。
root@localhost:/sys/fs/cgroup/cpu/cgroup1# pgrep xmrig
14761
root@localhost:/sys/fs/cgroup/cpu/cgroup1# ll
total 0
drwxr-xr-x 2 root root 0 May 27 22:26 ./
dr-xr-xr-x 6 root root 0 May 27 22:26 ../
-rw-r--r-- 1 root root 0 May 27 22:26 cgroup.clone_children
-rw-r--r-- 1 root root 0 May 30 17:40 cgroup.procs
-r--r--r-- 1 root root 0 May 27 22:26 cpuacct.stat
-rw-r--r-- 1 root root 0 May 27 22:26 cpuacct.usage
-r--r--r-- 1 root root 0 May 27 22:26 cpuacct.usage_percpu
-rw-r--r-- 1 root root 0 May 27 22:26 cpu.cfs_period_us
-rw-r--r-- 1 root root 0 May 27 22:28 cpu.cfs_quota_us
-rw-r--r-- 1 root root 0 May 27 22:26 cpu.shares
-r--r--r-- 1 root root 0 May 27 22:26 cpu.stat
-rw-r--r-- 1 root root 0 May 27 22:26 notify_on_release
-rw-r--r-- 1 root root 0 May 27 22:26 tasks
root@localhost:/sys/fs/cgroup/cpu/cgroup1# cat cgroup.procs
14761
root@localhost:/sys/fs/cgroup/cpu/cgroup1# cat cpu.cfs_period_us
100000
root@localhost:/sys/fs/cgroup/cpu/cgroup1# cat cpu.cfs_quota_us
160000