{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 tiancaidave 的文章《进程控制块PCB》','https://www.xiaopingtou.net/article-94490.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
注:本分类下文章大多整理自《深入分析linux内核源代码》一书,另有参考其他一些资料如《linux内核完全剖析》、《linux c 编程一站式学习》等,只是为了更好地理清系统编程和网络编程中的一些概念性问题,并没有深入地阅读分析源码,我也是草草翻过这本书,请有兴趣的朋友自己参考相关资料。此书出版较早,分析的版本为2.4.16,故出现的一些概念可能跟最新版本内核不同。
此书已经开源,阅读地址 http://www.kerneltravel.net
一、task_struct 结构描述
1.进程状态(State)
进程执行时,它会根据具体情况改变状态。进程状态是调度和对换的依据。Linux 中的进程主要有如下状态,如表4.1 所示。
(1)可运行状态 处于这种状态的进程,要么正在运行、要么正准备运行。正在运行的进程就是当前进程(由current 宏 所指向的进程),而准备运行的进程只要得到CPU 就可以立即投入运行,CPU 是这些进程唯一等待的系统资源。系统中有一个运行队列(run_queue),用来容纳所有处于可运行状态的进程,调度程序执行时,从中选择一个进程投入运行。当前运行进程一直处于该队列中,也就是说,current总是指向运行队列中的某个元素,只是具体指向谁由调度程序决定。
(2)等待状态 处于该状态的进程正在等待某个事件(Event)或某个资源,它肯定位于系统中的某个等待队列(wait_queue)中。Linux 中处于等待状态的进程分为两种:可中断的等待状态和不可中断的等待状态。处于可中断等待态的进程可以被信号唤醒,如果收到信号,该进程就从等待状态进入可运行状态,并且加入到运行队列中,等待被调度;而处于不可中断等待态的进程是因为硬件环境不能满足而等待,例如等待特定的系统资源,它任何情况下都不能被打断,只能用特定的方式来唤醒它,例如唤醒函数wake_up()等。
(3)暂停状态 此时的进程暂时停止运行来接受某种特殊处理。通常当进程接收到SIGSTOP、SIGTSTP、SIGTTIN 或 SIGTTOU 信号后就处于这种状态。例如,正接受调试的进程就处于这种状态。
(4)僵死状态 进程虽然已经终止,但由于某种原因,父进程还没有执行wait()系统调用,终止进程的信息也还没有回收。顾名思义,处于该状态的进程就是死进程,这种进程实际上是系统中的垃圾,必须进行相应处理以释放其占用的资源。
A child that terminates, but has not been waited for becomes a "zombie". The kernel maintains a
minimal set of information about the zombie process (PID, termination status, resource usage
information) in order to allow the parent to later perform a wait to obtain information about the
child. As long as a zombie is not removed from the system via a wait, it will consume a slot in
the kernel process table, and if this table fills, it will not be possible to create further
processes. If a parent process terminates, then its "zombie" children (if any) are adopted by
init(8), which automatically performs a wait to remove the zombies.
2.进程调度信息
调度程序利用这部分信息决定系统中哪个进程最应该运行,并结合进程的状态信息保证系统运转的公平和高效。这一部分信息通常包括进程的类别(普通进程还是实时进程)、进程的优先级等,如表4.2 所示。
当need_resched 被设置时,在“下一次的调度机会”就调用调度程序schedule();counter 代表进程剩余的时间片,是进程调度的主要依据,也可以说是进程的动态优先级,因为这个值在不断地减少;nice 是进程的静态优先级,同时也代表进程的时间片,用于对counter 赋值,可以用nice()系统调用改变这个值;policy是适用于该进程的调度策略,实时进程和普通进程的调度策略是不同的;rt_priority 只对实时进程有意义,它是实时进程调度的依据。
进程的调度策略有3 种,如表4.3 所示。
只有root 用户能通过sched_setscheduler()系统调用来改变调度策略。
3.标识符(Identifiers)
每个进程有进程标识符、用户标识符、组标识符,如表4.4 所示。不管对内核还是普通用户来说,怎么用一种简单的方式识别不同的进程呢?这就引入了进程标识符(PID,process identifier),每个进程都有一个唯一的标识符,内核通过这个标识符来识别不同的进程,同时,进程标识符PID 也是内核提供给用户程序的接口,用户程序通过PID 对进程发号施令。PID 是32 位的无符号整数,它被顺序编号:新创建进程的PID通常是前一个进程的PID 加1。然而,为了与16 位硬件平台的传统Linux 系统保持兼容,在Linux 上允许的最大PID 号是32767,当内核在系统中创建第32768 个进程时,就必须重新开始使用已闲置的PID 号。
4.进程通信有关信息(IPC,Inter_Process Communication)
为了使进程能在同一项任务上协调工作,进程之间必须能进行通信即交流数据。Linux 支持多种不同形式的通信机制。它支持典型的UNIX 通信机制(IPC Mechanisms):信号(Signals)、管道(Pipes),也支持System V / Posix 通信机制:共享内存(Shared Memory)、信号量和消息队列(Message Queues),如表4.5 所示。
5.进程链接信息(Links)
程序创建的进程具有父/子关系。因为一个进程能创建几个子进程,而子进程之间有兄弟关系,在task_struct 结构中有几个域来表示这种关系。在Linux 系统中,除了初始化进程init,其他进程都有一个父进程(Parent Process)。可以通过fork()或clone()系统调用来创建子进程,除了进程标识符(PID)等必要的信息外,子进程的task_struct 结构中的绝大部分的信息都是从父进程中拷贝。系统有必要记录这种“亲属”关系,使进程之间的协作更加方便,例如父进程给子进程发送杀死(kill)信号、父子进程通信等。每个进程的task_struct 结构有许多指针,通过这些指针,系统中所有进程的task_struct结构就构成了一棵进程树,这棵进程树的根就是初始化进程init的task_struct结构(init 进程是Linux 内核建立起来后人为创建的一个进程,是所有进程的祖先进程)。 表4.6 是进程所有的链接信息。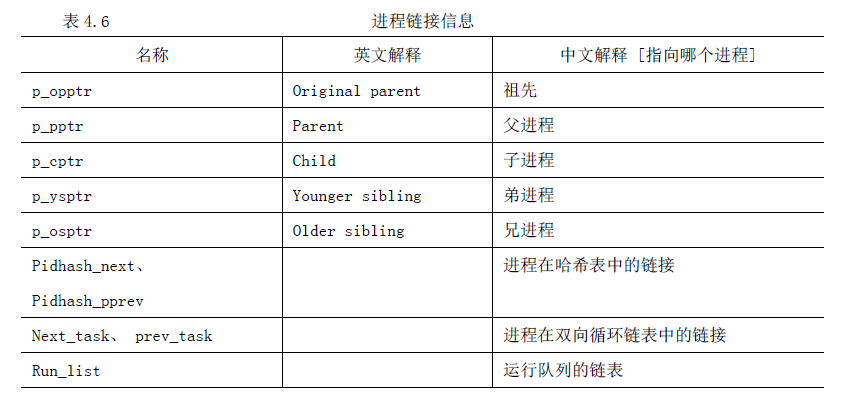
6.时间和定时器信息(Times and Timers)
一个进程从创建到终止叫做该进程的生存期(lifetime)。进程在其生存期内使用CPU的时间,内核都要进行记录,以便进行统计、计费等有关操作。进程耗费CPU 的时间由两部分组成:一是在用户模式(或称为用户态)下耗费的时间、一是在系统模式(或称为系统态)下耗费的时间。每个时钟滴答,也就是每个时钟中断,内核都要更新当前进程耗费CPU 的时间信息。
7.文件系统信息(File System)
进程可以打开或关闭文件,文件属于系统资源,Linux 内核要对进程使用文件的情况进行记录。task_struct 结构中有两个数据结构用于描述进程与文件相关的信息。其中,fs_struct 中描述了两个VFS 索引节点(VFS inode),这两个索引节点叫做root 和pwd,分别指向进程的可执行映像所对应的根目录(Home Directory)和当前目录或工作目录。file_struct 结构用来记录了进程打开的文件的描述符(Descriptor)。如表4.9 所示。
在文件系统中,每个VFS 索引节点唯一描述一个文件或目录,同时该节点也是向更低层的文件系统提供的统一的接口。
8.虚拟内存信息(Virtual Memory)
除了内核线程(Kernel Thread),每个进程都拥有自己的地址空间(也叫虚拟空间),用mm_struct 来描述。另外Linux 2.4 还引入了另外一个域active_mm,这是为内核线程而引入的。因为内核线程没有自己的地址空间,为了让内核线程与普通进程具有统一的上下文切换方式,当内核线程进行上下文切换时,让切换进来的线程的active_mm 指向刚被调度出去的进程的mm_struct。内存信息如表4.10 所示。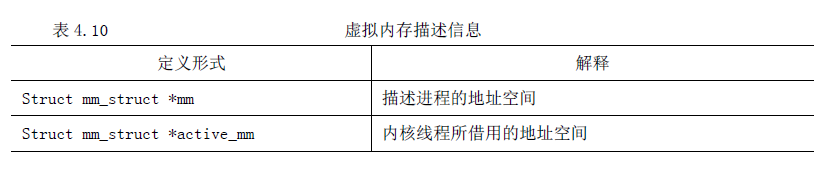
9.页面管理信息
当物理内存不足时,Linux 内存管理子系统需要把内存中的部分页面交换到外存,其交换是以页为单位的。有关页面的描述信息如表4.11。
10.对称多处理机(SMP)信息
Linux 2.4 对SMP 进行了全面的支持,表4.12 是与多处理机相关的几个域。
11.和处理器相关的环境(上下文)信息(Processor Specific Context)
这里要特别注意标题:和“处理器”相关的环境信息。进程作为一个执行环境的综合,当系统调度某个进程执行,即为该进程建立完整的环境时,处理器(Processor)的寄存器、堆栈等是必不可少的。因为不同的处理器对内部寄存器和堆栈的定义不尽相同,所以叫做“和处理器相关的环境”,也叫做“处理机状态”。当进程暂时停止运行时,处理机状态必须保存在进程的thread_struct 结构中,当进程被调度重新运行时再从中恢复这些环境,也就是恢复这些寄存器和堆栈的值。处理机信息如表4.13 所示。
12.其他
(1)struct wait_queue *wait_chldexit 在进程结束时,或发出系统调用wait 时,为了等待子进程的结束,而将自己(父进程)睡眠在该等待队列上,设置状态标志为TASK_INTERRUPTIBLE,并且把控制权转给调度程序。
(2)Struct rlimit rlim[RLIM_NLIMITS] 每一个进程可以通过系统调用setrlimit 和getrlimit 来限制它资源的使用。
(3)Int exit_code exit_signal 程序的返回代码以及程序异常终止产生的信号,这些数据由父进程(子进程完成后)轮流查询。
(4)Char comm[16] 这个域存储进程执行的程序的名字,这个名字用在调试中。
(5)Unsigned long personality Linux 可以运行X86 平台上其他UNIX 操作系统生成的符合iBCS2 标准的程序,personality 进一步描述进程执行的程序属于何种UNIX 平台的“个性”信息。通常有PER_Linux,PER_Linux_32BIT,PER_Linux_EM86,PER_SVR4,PER_SVR3,PER_SCOSVR3, PER_WYSEV386,PER_ISCR4,PER_BSD,PER_XENIX 和PER_MASK 等,参见include/Linux/personality.h>。
(6) int did_exec:1 按POSIX 要求设计的布尔量,区分进程正在执行老程序代码,还是用系统调用execve()装入一个新的程序。
(7)struct linux_binfmt *binfmt 指向进程所属的全局执行文件格式结构,共有a.out、script、elf、java 等4 种。
二、进程组织方式
1、内核栈
每个进程都有自己的内核栈,当进程从用户态进入内核态时,CPU 就自动地设置该进程的内核栈,也就是说,CPU 从任务状态段TSS 中装入内核栈指针esp,在/include/linux/sched.h 中定义了如下一个联合结构:
C++ Code 1
2
3
4
5
6
union task_union
{
struct task_struct task;
unsigned long stack[2048]; };

从这个结构可以看出,内核栈占8KB 的内存区。实际上,进程的task_struct 结构所占的内存是由内核动态分配的,更确切地说,内核根本不给task_struct 分配内存,而仅仅给内核栈分配8KB 的内存,并把其中的一部分给task_struct 使用。task_struct 结构大约占1K 字节左右,其具体数字与内核版本有关,因为不同的版本其域稍有不同。因此,内核栈的大小不能超过7KB,否则,内核栈会覆盖task_struct 结构,从而导致内核崩溃。不过,7KB 大小对内核栈已足够。
2、current 宏
当一个进程在某个CPU 上正在执行时,内核如何获得指向它的task_struct 的指针?在linux/include/i386/current.h 中 定义了current 宏,这是一段与体系结构相关的代码:
C++ Code 1
2
3
4
5
6
7
8
static inline struct task_struct *get_current(void)
{
struct task_struct *current;
__asm__("andl %%esp,%0; ":"=r" (current) : "0" (~8191UL));
return current;
}
3、哈希表
Linux 在进程中引入的哈希表叫做pidhash,在include/linux/sched.h 中定义如下:
C++ Code 1
2
3
4
#define PIDHASH_SZ (4096 >> 2)
extern struct task_struct *pidhash[PIDHASH_SZ];
#define pid_hashfn(x) ((((x) >> 8) ^ (x)) & (PIDHASH_SZ - 1))
其中,PIDHASH_SZ 为表中元素的个数,表中的元素是指向task_struct 结构的指针。pid_hashfn 为哈希函数,把进程的PID 转换为表的索引。通过这个函数,可以把进程的PID均匀地散列在它们的域(0 到 PID_MAX-1)中。
Linux 利用链地址法来处理冲突的PID:也就是说,每一表项是由冲突的PID 组成的双向链表,这种链表是由task_struct 结构中的pidhash_next 和 pidhash_pprev 域实现的,同一链表中pid 的大小由小到大排列。
4、双向循环链表
哈希表的主要作用是根据进程的pid 可以快速地找到对应的进程,但它没有反映进程创建的顺序,也无法反映进程之间的亲属关系,因此引入双向循环链表。每个进程task_struct结构中的prev_task 和next_task 域用来实现这种链表。
链表的头和尾都为init_task,它对应的是进程0(pid 为0),也就是所谓的空进程,它是所有进程的祖先。
5、运行队列
当内核要寻找一个新的进程在CPU 上运行时,必须只考虑处于可运行状态的进程(即在TASK_RUNNING 状态的进程),因为扫描整个进程链表是相当低效的,所以引入了可运行状态进程的双向循环链表,也叫运行队列(run queue)。
该队列通过task_struct 结构中的两个指针run_list 链表来维持。队列的标志有两个:一个是“空进程”idle_task;一个是队列的长度,,也就是系统中处于可运行状态(TASK_RUNNING)的进程数目,用全局整型变量nr_running 表示。
6、等待队列
进程必须经常等待某些事件的发生,例如,等待一个磁盘操作的终止,等待释放系统资源或等待时间走过固定的间隔。等待队列实现在 事件上的条件等待,也就是说,希望等待特定事件的进程把自己放进合适的等待队列,并放弃控制权。因此,等待队列表示一组睡眠的进程,当某一条件变为真时,由内核唤醒它们。等待队列由循环链表实现。
7、内核线程
内核线程(kernel thread)
这类线程周期性被内核唤醒和调度,主要用于实现系统后台操作,如页面对换,刷新磁盘缓存,网络连接等系统工作。
• 内核线程执行的是内核中的函数,而普通进程只有通过系统调用才能执行内核中的函数。 • 内核线程只运行在内核态,而普通进程既可以运行在用户态,也可以运行在内核态。 • 因为内核线程指只运行在内核态,因此,它只能使用大于PAGE_OFFSET(3G)的地址空间。另一方面,不管在用户态还是内核态,普通进程可以使用4GB 的地址空间。
一、task_struct 结构描述
1.进程状态(State)
进程执行时,它会根据具体情况改变状态。进程状态是调度和对换的依据。Linux 中的进程主要有如下状态,如表4.1 所示。
(1)可运行状态 处于这种状态的进程,要么正在运行、要么正准备运行。正在运行的进程就是当前进程(由current 宏 所指向的进程),而准备运行的进程只要得到CPU 就可以立即投入运行,CPU 是这些进程唯一等待的系统资源。系统中有一个运行队列(run_queue),用来容纳所有处于可运行状态的进程,调度程序执行时,从中选择一个进程投入运行。当前运行进程一直处于该队列中,也就是说,current总是指向运行队列中的某个元素,只是具体指向谁由调度程序决定。
(2)等待状态 处于该状态的进程正在等待某个事件(Event)或某个资源,它肯定位于系统中的某个等待队列(wait_queue)中。Linux 中处于等待状态的进程分为两种:可中断的等待状态和不可中断的等待状态。处于可中断等待态的进程可以被信号唤醒,如果收到信号,该进程就从等待状态进入可运行状态,并且加入到运行队列中,等待被调度;而处于不可中断等待态的进程是因为硬件环境不能满足而等待,例如等待特定的系统资源,它任何情况下都不能被打断,只能用特定的方式来唤醒它,例如唤醒函数wake_up()等。
(3)暂停状态 此时的进程暂时停止运行来接受某种特殊处理。通常当进程接收到SIGSTOP、SIGTSTP、SIGTTIN 或 SIGTTOU 信号后就处于这种状态。例如,正接受调试的进程就处于这种状态。
(4)僵死状态 进程虽然已经终止,但由于某种原因,父进程还没有执行wait()系统调用,终止进程的信息也还没有回收。顾名思义,处于该状态的进程就是死进程,这种进程实际上是系统中的垃圾,必须进行相应处理以释放其占用的资源。
A child that terminates, but has not been waited for becomes a "zombie". The kernel maintains a
minimal set of information about the zombie process (PID, termination status, resource usage
information) in order to allow the parent to later perform a wait to obtain information about the
child. As long as a zombie is not removed from the system via a wait, it will consume a slot in
the kernel process table, and if this table fills, it will not be possible to create further
processes. If a parent process terminates, then its "zombie" children (if any) are adopted by
init(8), which automatically performs a wait to remove the zombies.
2.进程调度信息
调度程序利用这部分信息决定系统中哪个进程最应该运行,并结合进程的状态信息保证系统运转的公平和高效。这一部分信息通常包括进程的类别(普通进程还是实时进程)、进程的优先级等,如表4.2 所示。
当need_resched 被设置时,在“下一次的调度机会”就调用调度程序schedule();counter 代表进程剩余的时间片,是进程调度的主要依据,也可以说是进程的动态优先级,因为这个值在不断地减少;nice 是进程的静态优先级,同时也代表进程的时间片,用于对counter 赋值,可以用nice()系统调用改变这个值;policy是适用于该进程的调度策略,实时进程和普通进程的调度策略是不同的;rt_priority 只对实时进程有意义,它是实时进程调度的依据。
进程的调度策略有3 种,如表4.3 所示。
只有root 用户能通过sched_setscheduler()系统调用来改变调度策略。
3.标识符(Identifiers)
每个进程有进程标识符、用户标识符、组标识符,如表4.4 所示。不管对内核还是普通用户来说,怎么用一种简单的方式识别不同的进程呢?这就引入了进程标识符(PID,process identifier),每个进程都有一个唯一的标识符,内核通过这个标识符来识别不同的进程,同时,进程标识符PID 也是内核提供给用户程序的接口,用户程序通过PID 对进程发号施令。PID 是32 位的无符号整数,它被顺序编号:新创建进程的PID通常是前一个进程的PID 加1。然而,为了与16 位硬件平台的传统Linux 系统保持兼容,在Linux 上允许的最大PID 号是32767,当内核在系统中创建第32768 个进程时,就必须重新开始使用已闲置的PID 号。
4.进程通信有关信息(IPC,Inter_Process Communication)
为了使进程能在同一项任务上协调工作,进程之间必须能进行通信即交流数据。Linux 支持多种不同形式的通信机制。它支持典型的UNIX 通信机制(IPC Mechanisms):信号(Signals)、管道(Pipes),也支持System V / Posix 通信机制:共享内存(Shared Memory)、信号量和消息队列(Message Queues),如表4.5 所示。
5.进程链接信息(Links)
程序创建的进程具有父/子关系。因为一个进程能创建几个子进程,而子进程之间有兄弟关系,在task_struct 结构中有几个域来表示这种关系。在Linux 系统中,除了初始化进程init,其他进程都有一个父进程(Parent Process)。可以通过fork()或clone()系统调用来创建子进程,除了进程标识符(PID)等必要的信息外,子进程的task_struct 结构中的绝大部分的信息都是从父进程中拷贝。系统有必要记录这种“亲属”关系,使进程之间的协作更加方便,例如父进程给子进程发送杀死(kill)信号、父子进程通信等。每个进程的task_struct 结构有许多指针,通过这些指针,系统中所有进程的task_struct结构就构成了一棵进程树,这棵进程树的根就是初始化进程init的task_struct结构(init 进程是Linux 内核建立起来后人为创建的一个进程,是所有进程的祖先进程)。 表4.6 是进程所有的链接信息。
6.时间和定时器信息(Times and Timers)
一个进程从创建到终止叫做该进程的生存期(lifetime)。进程在其生存期内使用CPU的时间,内核都要进行记录,以便进行统计、计费等有关操作。进程耗费CPU 的时间由两部分组成:一是在用户模式(或称为用户态)下耗费的时间、一是在系统模式(或称为系统态)下耗费的时间。每个时钟滴答,也就是每个时钟中断,内核都要更新当前进程耗费CPU 的时间信息。
7.文件系统信息(File System)
进程可以打开或关闭文件,文件属于系统资源,Linux 内核要对进程使用文件的情况进行记录。task_struct 结构中有两个数据结构用于描述进程与文件相关的信息。其中,fs_struct 中描述了两个VFS 索引节点(VFS inode),这两个索引节点叫做root 和pwd,分别指向进程的可执行映像所对应的根目录(Home Directory)和当前目录或工作目录。file_struct 结构用来记录了进程打开的文件的描述符(Descriptor)。如表4.9 所示。
在文件系统中,每个VFS 索引节点唯一描述一个文件或目录,同时该节点也是向更低层的文件系统提供的统一的接口。
8.虚拟内存信息(Virtual Memory)
除了内核线程(Kernel Thread),每个进程都拥有自己的地址空间(也叫虚拟空间),用mm_struct 来描述。另外Linux 2.4 还引入了另外一个域active_mm,这是为内核线程而引入的。因为内核线程没有自己的地址空间,为了让内核线程与普通进程具有统一的上下文切换方式,当内核线程进行上下文切换时,让切换进来的线程的active_mm 指向刚被调度出去的进程的mm_struct。内存信息如表4.10 所示。
9.页面管理信息
当物理内存不足时,Linux 内存管理子系统需要把内存中的部分页面交换到外存,其交换是以页为单位的。有关页面的描述信息如表4.11。
10.对称多处理机(SMP)信息
Linux 2.4 对SMP 进行了全面的支持,表4.12 是与多处理机相关的几个域。
11.和处理器相关的环境(上下文)信息(Processor Specific Context)
这里要特别注意标题:和“处理器”相关的环境信息。进程作为一个执行环境的综合,当系统调度某个进程执行,即为该进程建立完整的环境时,处理器(Processor)的寄存器、堆栈等是必不可少的。因为不同的处理器对内部寄存器和堆栈的定义不尽相同,所以叫做“和处理器相关的环境”,也叫做“处理机状态”。当进程暂时停止运行时,处理机状态必须保存在进程的thread_struct 结构中,当进程被调度重新运行时再从中恢复这些环境,也就是恢复这些寄存器和堆栈的值。处理机信息如表4.13 所示。
12.其他
(1)struct wait_queue *wait_chldexit 在进程结束时,或发出系统调用wait 时,为了等待子进程的结束,而将自己(父进程)睡眠在该等待队列上,设置状态标志为TASK_INTERRUPTIBLE,并且把控制权转给调度程序。
(2)Struct rlimit rlim[RLIM_NLIMITS] 每一个进程可以通过系统调用setrlimit 和getrlimit 来限制它资源的使用。
(3)Int exit_code exit_signal 程序的返回代码以及程序异常终止产生的信号,这些数据由父进程(子进程完成后)轮流查询。
(4)Char comm[16] 这个域存储进程执行的程序的名字,这个名字用在调试中。
(5)Unsigned long personality Linux 可以运行X86 平台上其他UNIX 操作系统生成的符合iBCS2 标准的程序,personality 进一步描述进程执行的程序属于何种UNIX 平台的“个性”信息。通常有PER_Linux,PER_Linux_32BIT,PER_Linux_EM86,PER_SVR4,PER_SVR3,PER_SCOSVR3, PER_WYSEV386,PER_ISCR4,PER_BSD,PER_XENIX 和PER_MASK 等,参见include/Linux/personality.h>。
(6) int did_exec:1 按POSIX 要求设计的布尔量,区分进程正在执行老程序代码,还是用系统调用execve()装入一个新的程序。
(7)struct linux_binfmt *binfmt 指向进程所属的全局执行文件格式结构,共有a.out、script、elf、java 等4 种。
二、进程组织方式
1、内核栈
每个进程都有自己的内核栈,当进程从用户态进入内核态时,CPU 就自动地设置该进程的内核栈,也就是说,CPU 从任务状态段TSS 中装入内核栈指针esp,在/include/linux/sched.h 中定义了如下一个联合结构:
C++ Code 1
2
3
4
5
6
union task_union
{
struct task_struct task;
unsigned long stack[2048]; };
从这个结构可以看出,内核栈占8KB 的内存区。实际上,进程的task_struct 结构所占的内存是由内核动态分配的,更确切地说,内核根本不给task_struct 分配内存,而仅仅给内核栈分配8KB 的内存,并把其中的一部分给task_struct 使用。task_struct 结构大约占1K 字节左右,其具体数字与内核版本有关,因为不同的版本其域稍有不同。因此,内核栈的大小不能超过7KB,否则,内核栈会覆盖task_struct 结构,从而导致内核崩溃。不过,7KB 大小对内核栈已足够。
2、current 宏
当一个进程在某个CPU 上正在执行时,内核如何获得指向它的task_struct 的指针?在linux/include/i386/current.h 中 定义了current 宏,这是一段与体系结构相关的代码:
C++ Code 1
2
3
4
5
6
7
8
static inline struct task_struct *get_current(void)
{
struct task_struct *current;
__asm__("andl %%esp,%0; ":"=r" (current) : "0" (~8191UL));
return current;
}
3、哈希表
Linux 在进程中引入的哈希表叫做pidhash,在include/linux/sched.h 中定义如下:
C++ Code 1
2
3
4
#define PIDHASH_SZ (4096 >> 2)
extern struct task_struct *pidhash[PIDHASH_SZ];
#define pid_hashfn(x) ((((x) >> 8) ^ (x)) & (PIDHASH_SZ - 1))
其中,PIDHASH_SZ 为表中元素的个数,表中的元素是指向task_struct 结构的指针。pid_hashfn 为哈希函数,把进程的PID 转换为表的索引。通过这个函数,可以把进程的PID均匀地散列在它们的域(0 到 PID_MAX-1)中。
Linux 利用链地址法来处理冲突的PID:也就是说,每一表项是由冲突的PID 组成的双向链表,这种链表是由task_struct 结构中的pidhash_next 和 pidhash_pprev 域实现的,同一链表中pid 的大小由小到大排列。
4、双向循环链表
哈希表的主要作用是根据进程的pid 可以快速地找到对应的进程,但它没有反映进程创建的顺序,也无法反映进程之间的亲属关系,因此引入双向循环链表。每个进程task_struct结构中的prev_task 和next_task 域用来实现这种链表。
链表的头和尾都为init_task,它对应的是进程0(pid 为0),也就是所谓的空进程,它是所有进程的祖先。
5、运行队列
当内核要寻找一个新的进程在CPU 上运行时,必须只考虑处于可运行状态的进程(即在TASK_RUNNING 状态的进程),因为扫描整个进程链表是相当低效的,所以引入了可运行状态进程的双向循环链表,也叫运行队列(run queue)。
该队列通过task_struct 结构中的两个指针run_list 链表来维持。队列的标志有两个:一个是“空进程”idle_task;一个是队列的长度,,也就是系统中处于可运行状态(TASK_RUNNING)的进程数目,用全局整型变量nr_running 表示。
6、等待队列
进程必须经常等待某些事件的发生,例如,等待一个磁盘操作的终止,等待释放系统资源或等待时间走过固定的间隔。等待队列实现在 事件上的条件等待,也就是说,希望等待特定事件的进程把自己放进合适的等待队列,并放弃控制权。因此,等待队列表示一组睡眠的进程,当某一条件变为真时,由内核唤醒它们。等待队列由循环链表实现。
7、内核线程
内核线程(kernel thread)
这类线程周期性被内核唤醒和调度,主要用于实现系统后台操作,如页面对换,刷新磁盘缓存,网络连接等系统工作。
• 内核线程执行的是内核中的函数,而普通进程只有通过系统调用才能执行内核中的函数。 • 内核线程只运行在内核态,而普通进程既可以运行在用户态,也可以运行在内核态。 • 因为内核线程指只运行在内核态,因此,它只能使用大于PAGE_OFFSET(3G)的地址空间。另一方面,不管在用户态还是内核态,普通进程可以使用4GB 的地址空间。