{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 zjw5000 的文章《Linux的进程------进程的描述和进程的创建》','https://www.xiaopingtou.net/article-94884.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
王雪 原创作品转载请注明出处 《Linux内核分析》MOOC课程 http://mooc.study.163.com/course/USTC-1000029000
一、基础知识
(1)操作系统的三个重要功能:进程管理、文件管理、内存管理
(2)为了管理进程,内核必须对每个进程进行清晰的描述,进程控制块PCB就完成了对进行描述的功能,进程控制块PCB——对应的task_struct(进程描述符)结构体,提供了内核需要了解的进程信息。
1.struct task_struct{……};里面的重要结构:
task_ struct在linux-3.18.6/include/linux/sched.h中定义
内容很多,例如:
进程的状态:

进程pid:唯一标识一个进程
进程链表的操作:

对进程链表的操作实质上就是双向链表的操作,通过对进程链表节点的创建插入和删除,完成进程的创建调度和结束释放等操作。
进程的内核堆栈:
1.Thread_info(在thread _ union中定义)
2.进程的内核堆栈
(每个进程都有自己独立的4G地址空间)
(3)解决问题:进程是如何被创建起来的?fork函数是怎么执行的?fork出来的子进程从哪里开始执行?
1.fork()的系统调用
2.创建一个新进程在内核中的执行过程
fork、vfork和clone三个系统调用都可以创建一个新进程,而且都是通过调用do_fork来实现进程的创建;Linux通过复制父进程来创建一个新进程
复制父进程的PCB,要在某个位置可以修改父进程的PCB内容变为子进程自己的,应有位置分配一个新的内核堆栈,子进程从fork的系统调用返回到用户态时,可以知道返回的位置,所以还要在新的内核堆栈里保存上父进程的信息。
大致过程:
1)复制一个PCB——task_struct
4)从用户态的代码看fork();函数返回了两次,即在父子进程中各返回一次,子进程从系统调用中返回,那它在系统调用处理过程开始执行的位置以及
子进程的内核堆栈数据状态和task_struct中thread记录的sp和ip的一致性问题都需要设定。
copy_ process()中,开始时检测clone_ flag中的标志位,看看是否允许copy。然后就是创建两个结构体,task_ struck和thread_ info,用来保存子进程的信息,然后将父进程中的这两个地方的信息复制过来,存到刚刚创建的结构体中。然后更新一下系统中,关于进程数量等信息,更改一下子进程的clone_ flag信息。设置子进程运行的CPU,把子进程加入到运行队列。
在copy_ process中
也就是说childregs指向 “子进程的栈顶 减去 一个sizeof(struct pt_regs)的大小 的地方”
子进程堆栈空间示意图:

5)子进程从哪里启动
在entry_ 32.S找到ret from work,标识了 p->thread.ip,当子进程获得CPU从内核态返回到用户态,在内核态中是从ret _ from _ work开始执行的。
ret_from _ work 会跳转到sys _ call _exit(这时的状态与调用前是相同的),从iret返回用户态,此时的内核空间变为子进程的内核空间。
二、gdb追踪进程创建的过程
添加系统menu的fork系统调用
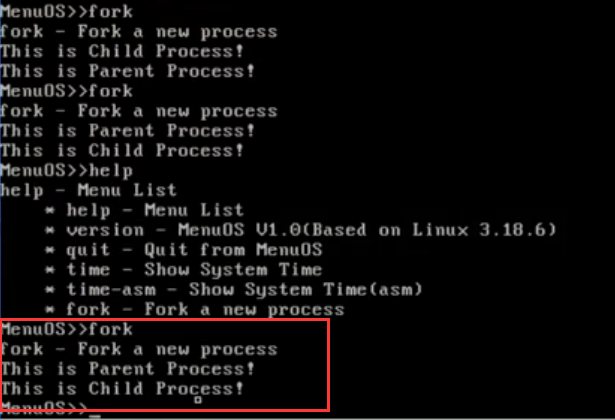
在sys_ clone(fork进行的系统调用)、do_fork、dup task struct、 copy _process ,copy _thread进行追踪查看,验证前面的过程,可以查看运行过程。
设置好断点后执行 fork,继续执行,程序停在do_ fork的位置,继续单步调式,可以看到相关的函数执行调用的过程。

三、总结
进程管理是操作系统功能的重要组成部分,是理解操作系统的关键,对于fork这个系统调用(调用一次,返回两次)要记住子进程是如何被创建起来的,都拷贝了父进程的哪些信息,修改了哪些信息,子进程是如何找到返回位置的,它在内核中是如何执行起来的等等。
(1)操作系统的三个重要功能:进程管理、文件管理、内存管理
(2)为了管理进程,内核必须对每个进程进行清晰的描述,进程控制块PCB就完成了对进行描述的功能,进程控制块PCB——对应的task_struct(进程描述符)结构体,提供了内核需要了解的进程信息。
1.struct task_struct{……};里面的重要结构:
task_ struct在linux-3.18.6/include/linux/sched.h中定义
内容很多,例如:
进程的状态:
volatile long state;
/* -1 unrunnable, 0 runnable, >0 stopped */
进程状态转换图,注意两个task_running状态 进程pid:唯一标识一个进程
pid_t pid;
pid_t tgid;
进程链表:
struct list_head tasks;
用于链接进程,定义在include/linux/list.h。 进程链表的操作:
对进程链表的操作实质上就是双向链表的操作,通过对进程链表节点的创建插入和删除,完成进程的创建调度和结束释放等操作。
进程的内核堆栈:
void *stack;
Linux为每个进程分配一个8KB大小的内存区域,用于存放该进程两个不同的数据结构: 1.Thread_info(在thread _ union中定义)
2.进程的内核堆栈
(每个进程都有自己独立的4G地址空间)
union thread_union {
struct thread_info thread_info;
unsigned long stack[THREAD_SIZE/sizeof(long)];
};
与内存管理相关的结构
struct mm_struct *mm,*active_mm;
此外还有很多,如文件系统和文件描述符,任务状态等等。 (3)解决问题:进程是如何被创建起来的?fork函数是怎么执行的?fork出来的子进程从哪里开始执行?
1.fork()的系统调用
#include
fork()调用一次返回两次,只不过返回的分别为父进程和子进程,也就是说,上面的代码有三种返回值,如果fork返回-1代表创建失败,结束。fork在子进程中会返回0,在父进程中会返回子进程pid(>0)。 2.创建一个新进程在内核中的执行过程
fork、vfork和clone三个系统调用都可以创建一个新进程,而且都是通过调用do_fork来实现进程的创建;Linux通过复制父进程来创建一个新进程
复制父进程的PCB,要在某个位置可以修改父进程的PCB内容变为子进程自己的,应有位置分配一个新的内核堆栈,子进程从fork的系统调用返回到用户态时,可以知道返回的位置,所以还要在新的内核堆栈里保存上父进程的信息。
大致过程:
1)复制一个PCB——task_struct
err = arch_dup_task_struct(tsk, orig);
2)要给新进程分配一个新的内核堆栈
ti = alloc_thread_info_node(tsk, node);
tsk->stack = ti;
setup_thread_stack(tsk, orig);
//这里只是复制thread_info,而非复制内核堆栈
3)修改复制过来的进程数据,比如pid、进程链表等(在copy_process中) 4)从用户态的代码看fork();函数返回了两次,即在父子进程中各返回一次,子进程从系统调用中返回,那它在系统调用处理过程开始执行的位置以及
子进程的内核堆栈数据状态和task_struct中thread记录的sp和ip的一致性问题都需要设定。
*childregs = *current_pt_regs();
//复制内核堆栈
childregs->ax = 0;
//为什么子进程的fork返回0,这里就是原因!
p->thread.sp = (unsigned long) childregs;
//调度到子进程时的内核栈顶
p->thread.ip = (unsigned long) ret_from_fork;
//调度到子进程时的第一条指令地址
3.进入linux-3.18/kernel/fork.c查看do_fork系统调用,在do fork中调用了copy process: copy_ process()中,开始时检测clone_ flag中的标志位,看看是否允许copy。然后就是创建两个结构体,task_ struck和thread_ info,用来保存子进程的信息,然后将父进程中的这两个地方的信息复制过来,存到刚刚创建的结构体中。然后更新一下系统中,关于进程数量等信息,更改一下子进程的clone_ flag信息。设置子进程运行的CPU,把子进程加入到运行队列。
p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace);
这个函数copy_ processs中调用了dup _ task_ struct 用于赋值当前PCB
/*fpu相关操作*/
prepare_to_copy(orig);
/*通过alloc_task_struct()函数创建task_struct结构空间*/
tsk = alloc_task_struct();
......
/*分配thread_info结构空间,可以看到order为1,也就是两个页面*/
ti = alloc_thread_info(tsk);
......
tsk->stack = ti;/*task的对应栈*/
......
/*初始化thread info结构*/
setup_thread_stack(tsk, orig);
stackend = end_of_stack(tsk);/*返回的是栈结束的地址*/
......
到结束,基本完成了PCB的复制. 在copy_ process中
p = dup_task_struct(current);
获得dup_task _struct返回的地址,用p指向当前进程的PCB,调用需要修改的内容进行修改,然后
retval = copy_thread(clone_flags, stack_start, stack_size, p);
copy_thread这个函数在process _32.c中定义。
struct pt_regs *childregs;
struct task_struct *tsk;
int err;
childregs = task_pt_regs(p);
//相当于childregs = ((struct pt_regs *) (THREAD_SIZE + (unsigned long) p)) - 1;
//这儿是先转为struct pt_regs后再减1
//这是在栈顶留出一个struct pt_regs的大小
//保存父寄存器的值到自己存器中;
//先将父进程的全部regs复制过来,然后再作调整
*childregs = *regs;
childregs->ax = 0;
childregs->sp = sp;
p->thread.sp = (unsigned long) childregs;
//执行后p->thread.esp=(p-sizeof(pt_regs))
p->thread.sp0 = (unsigned long) (childregs+1);
//执行后p->thread.esp0=(p),即将两页内存的最高端作为栈顶
p->thread.ip = (unsigned long) ret_from_fork;
//下次调度时子进程执行的命令是ret_form_fork
childregs = task_ pt _ regs(p); 实际上是–> childregs = ((struct pt_ regs *) (THREAD_ SIZE + (unsigned long) p)) - 1; 也就是说childregs指向 “子进程的栈顶 减去 一个sizeof(struct pt_regs)的大小 的地方”
子进程堆栈空间示意图:
5)子进程从哪里启动
在entry_ 32.S找到ret from work,标识了 p->thread.ip,当子进程获得CPU从内核态返回到用户态,在内核态中是从ret _ from _ work开始执行的。
ret_from _ work 会跳转到sys _ call _exit(这时的状态与调用前是相同的),从iret返回用户态,此时的内核空间变为子进程的内核空间。
二、gdb追踪进程创建的过程
添加系统menu的fork系统调用
在sys_ clone(fork进行的系统调用)、do_fork、dup task struct、 copy _process ,copy _thread进行追踪查看,验证前面的过程,可以查看运行过程。
设置好断点后执行 fork,继续执行,程序停在do_ fork的位置,继续单步调式,可以看到相关的函数执行调用的过程。
三、总结
进程管理是操作系统功能的重要组成部分,是理解操作系统的关键,对于fork这个系统调用(调用一次,返回两次)要记住子进程是如何被创建起来的,都拷贝了父进程的哪些信息,修改了哪些信息,子进程是如何找到返回位置的,它在内核中是如何执行起来的等等。